Это делается достаточно просто через:
* Хинт
/*+ parallel(N) */
* Через установки сессий:
alter session enable parallel dml; --для insert ALTER SESSION FORCE PARALLEL QUERY PARALLEL N;
- N число потоков
В теории этого достаточно, чтобы ускорить запрос в разы.
Но есть ряд ситуаций в которых параллельность наоборот мешает.
Для начала разберемся с терминологией - посмотрим на параллельный план с join 2 таблиц:
create table t_1
compress
as
select /*+ use_nl(a b) */
rownum as id
, rpad('x', 100) as filler
from
(select /*+ cardinality(1e5) */ * from dual
connect by
level <= 1e5) a, (select /*+ cardinality(20) */ * from dual connect by level <= 20) b
;
create table t_2
compress
as
select
rownum as id
, case when rownum <= 5e5 then mod(rownum, 2e6) + 1 else 1 end as fk_id_skew
, rownum as fk_id_uniform
, rpad('x', 100) as filler
from
(select /*+ cardinality(1e5) */ * from dual
connect by
level <= 1e5) a, (select /*+ cardinality(20) */ * from dual connect by level <= 20) b
;
--соберем статистику
begin
dbms_stats.gather_table_stats(user, 't_1');
dbms_stats.gather_table_stats(user, 't_2');
end;
/
- Запрос 1Таблица T2 имеет особенность: fk_id_skew неравномерно заполнен и имеет перекос в сторону 1 - она встречается значительно чаще других.
select COUNT(*) cnt, fk_id_skew from t_2 GROUP BY fk_id_skew ORDER BY cnt desc;
CNT FK_ID_SKEW
---------- ----------
1500000 1
1 22
1 30
1 34
....
- Запрос 2Итак, выполнил простой запрос:
select count(t_2_filler) from (
select /*+ monitor
no_parallel
leading(t_1 t_2)
use_hash(t_2)
no_swap_join_inputs(t_2)
*/
t_1.id as t_1_id
, t_1.filler as t_1_filler
, t_2.id as t_2_id
, t_2.filler as t_2_filler
from t_1
, t_2
where
t_2.fk_id_uniform = t_1.id
and regexp_replace(t_2.filler, '^\s+([[:alnum:]]+)\s+$', lpad('\1', 10), 1, 1, 'c') >= regexp_replace(t_1.filler, '^\s+([[:alnum:]]+)\s+$', lpad('\1', 10), 1, 1, 'c')
);
- Запрос 3* regexp_replace в этом запросе нужен, чтобы данные отбирались не мгновенно и были видны в статистике затраты CPU.
* Хинты вставлены, чтобы запрос в плане выглядел также как написан тут.
Время выполнения выполнения запроса = 49сек.
Добавим хинт parallel(8) замен no_parallel.
Время выполнения = 8с, что в 6 раз быстрей.
Разберем для понимания план запроса:
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY(format=>'PARALLEL')); ------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib | ------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 213 | 619 (2)| 00:00:08 | | | | | 1 | SORT AGGREGATE | | 1 | 213 | | | | | | | 2 | PX COORDINATOR | | | | | | | | | | 3 | PX SEND QC (RANDOM) | :TQ10002 | 1 | 213 | | | Q1,02 | P->S | QC (RAND) | | 4 | SORT AGGREGATE | | 1 | 213 | | | Q1,02 | PCWP | | |* 5 | HASH JOIN | | 100K| 20M| 619 (2)| 00:00:08 | Q1,02 | PCWP | | | 6 | PX RECEIVE | | 2000K| 202M| 245 (2)| 00:00:03 | Q1,02 | PCWP | | | 7 | PX SEND HASH | :TQ10000 | 2000K| 202M| 245 (2)| 00:00:03 | Q1,00 | P->P | HASH | | 8 | PX BLOCK ITERATOR | | 2000K| 202M| 245 (2)| 00:00:03 | Q1,00 | PCWC | | | 9 | TABLE ACCESS FULL| T_1 | 2000K| 202M| 245 (2)| 00:00:03 | Q1,00 | PCWP | | | 10 | PX RECEIVE | | 2000K| 204M| 371 (1)| 00:00:05 | Q1,02 | PCWP | | | 11 | PX SEND HASH | :TQ10001 | 2000K| 204M| 371 (1)| 00:00:05 | Q1,01 | P->P | HASH | | 12 | PX BLOCK ITERATOR | | 2000K| 204M| 371 (1)| 00:00:05 | Q1,01 | PCWC | | | 13 | TABLE ACCESS FULL| T_2 | 2000K| 204M| 371 (1)| 00:00:05 | Q1,01 | PCWP | | -------------------------------------------------------------------------------------------------------------------- План 1
Основопологающие фазы:
* PX BLOCK ITERATOR - чтение таблицы частями в несколько потоков
* PX SEND - 1 поток посылает данные другому. Важно знать, что только один producer (PX SEND) может быть активен в одно время, что накладывает ограничения на параллельный план выполнения, подробней: Вторая часть по распределению данных в параллельных запросах
** RANGE - данные будут разбиты на диапазоны (часто при сортировке)
** HASH - диапазон данных на основе их хэша (hash join, group by)
** RANDOM - случайная отправка
** BROADCAST - отправка таблицы во все потоки (часто на маленькой таблице, совместно с последующей ROUND ROBIN правой таблицы. Может быть проблемой производительности, если левая таблица значительно больше, чем указано в статистике, т.к. данные дублируются во все потоки)
** ROUND ROBIN - данные отправляются в потоки по кругу
Про способы распределения данных по потокам нужно поговорить отдельно:
Стоит заметить, что данные бьются по значениям в столбцах строк, а не просто по строкам.
Это нужно, чтобы один и тотже диапозон данных из разных таблиц попал в один поток для join.
Если бы Oracle делал не так, то в 1 поток могли бы попасть совершенно разные данные и join нельзя было бы совершить.
На это стоит обратить внимание, т.к. это может являться и причиной замедлений выполнения параллельного запроса при сильном перекосе данных (О причинах замделенния параллельных запросов дальше)
** P->S - параллельность в последовательное выполнение (узкое место или конец запроса - вторая из основных причин замедления параллельного запроса)
** PCWP - параллельность с родителем: сканируем таблицу и сразу делаем join с другой
** PCWC - наоборот: передаем фильтр из внешнего потока и применяем при сканировании
* PX RECEIVE - получение данных из одного параллельного потока в другой
* PX SEND QC - отправка данных координатору
* PX COORDINATOR - приемник всех параллельных запросов
* TQ - Номер потока
Мы рассмотрели идеальный случай распараллеленого запроса. Остановимся подробней на причинах замеделений:
1. Событие "P->S - параллельность в последовательное выполнение"
2. PX SEND skew - Перекос данных
и ускорения:
3. Bloom filter
4. Partition wise
1. Наличие в плане события "P->S - параллельность в последовательное выполнение", кроме перед "PX COORDINATOR"
Это говорит нам о том, что Oracle вынужден был собрать все потоки в одну последовательность (sequence), что дало бутылочное горлышко ожидания выполнения самого долго потока всеми остальными.
Самыми частыми причинами этого является:
* при добавлении pl/sql функции в запрос, которая не может быть распараллелена
Обойти можно только если функция детерменестическая, когда ее результат зависит только от параметров (никаких вызовов за пределы функции):
** Диррективы determenistic и result cache при создании функции
** Устаревший (но рабочий) deprecated способ с константым доступом к функции через pragma ( http://docs.oracle.com/cd/B28359_01/appdev.111/b28370/restrictreferences_pragma.htm )
PRAGMA RESTRICT_REFERENCES (FNC, RNDS, WNDS, RNPS, WNPS)
* наличие иерархичных запросов CONNECT BY
* наличие доступа по DB LINK
* наличие псевдостолбца с номеро строки ROWNUM
ROWNUM/CONNECT BY/DB LINK желательно исключать из параллельных запросов, но если такой возможности нет, то максимально их изолировать через materialized with
* index range scan - последовательное сканирование индекса
* Плохо работает с сессионной переменной "_disable_cursor_sharing"=true , форсирующей новый разбор кода sql заново.
Катастрофически растет событие ожидания "cursor pin s wait" - поиск подходящего дочернего курсора из подмножества вариантов.
Подробное описание: https://iusoltsev.wordpress.com/2012/06/04/force-sql-parse-_disable_cursor_sharing-11-2-0-3/
Приведу пример с rownum. Добавим отбор номера строки из каждой таблицы:
select count(t_2_filler) from (
select /*+ monitor
leading(t_1 t_2)
use_hash(t_2)
no_swap_join_inputs(t_2)
parallel(8)
*/
t_1.id as t_1_id
, t_1.filler as t_1_filler
, t_2.id as t_2_id
, t_2.filler as t_2_filler
from (select t_1.*, rownum as rn from t_1) t_1
,(select t_2.*, rownum as rn from t_2) t_2
where
t_2.fk_id_uniform = t_1.id
and regexp_replace(t_2.filler, '^\s+([[:alnum:]]+)\s+$', lpad('\1', 10), 1, 1, 'c') >= regexp_replace(t_1.filler, '^\s+([[:alnum:]]+)\s+$', lpad('\1', 10), 1, 1, 'c')
);
План поменялся, * для расчета COUNT rownum параллельный процесс чтения таблицы с диска "PX BLOCK ITERATOR" выстраивается в очередь "P->S", что сводит на нет все перимещуство распределенного чтения.
* теперь JOIN не выполняется в отдельном потоке ( :TQ10002 )
т.к. оба потока уже были раньше преобразованы в последовательный набор данных и не могут использоваться одновременно.
------------------------------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib | ------------------------------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | 116 | 310 (2)| 00:00:01 | | | | | 1 | SORT AGGREGATE | | 1 | 116 | | | | | | |* 2 | HASH JOIN | | 100K| 11M| 310 (2)| 00:00:01 | | | | | 3 | VIEW | | 2000K| 110M| 122 (1)| 00:00:01 | | | | | 4 | COUNT | | | | | | | | | | 5 | PX COORDINATOR | | | | | | | | | | 6 | PX SEND QC (RANDOM)| :TQ10000 | 2000K| 202M| 122 (1)| 00:00:01 | Q1,00 | P->S | QC (RAND) | | 7 | PX BLOCK ITERATOR | | 2000K| 202M| 122 (1)| 00:00:01 | Q1,00 | PCWC | | | 8 | TABLE ACCESS FULL| T_1 | 2000K| 202M| 122 (1)| 00:00:01 | Q1,00 | PCWP | | | 9 | VIEW | | 2000K| 110M| 186 (2)| 00:00:01 | | | | | 10 | COUNT | | | | | | | | | | 11 | PX COORDINATOR | | | | | | | | | | 12 | PX SEND QC (RANDOM)| :TQ20000 | 2000K| 204M| 186 (2)| 00:00:01 | Q2,00 | P->S | QC (RAND) | | 13 | PX BLOCK ITERATOR | | 2000K| 204M| 186 (2)| 00:00:01 | Q2,00 | PCWC | | | 14 | TABLE ACCESS FULL| T_2 | 2000K| 204M| 186 (2)| 00:00:01 | Q2,00 | PCWP | | ------------------------------------------------------------------------------------------------------------------Как следствие, время выполнения запроса стало даже больше ( 51 с ), чем не параллельная версия (49 с ) из-за лишних издержек на поддержку параллельности, которая не используется
2. PX SEND skew - Перекос данных
при формировании диапозонов данных в один из потоков.
Продемонстрировать это просто используя заранее созданный перекошенный столбец t_2.fk_id_skew.
Если выполнить запрос, но для join таблиц использовать условие: t_2.fk_id_skew = t_1.id
То общий план параллельного запроса не поменяется (см. План 1 ), но вот время выполнения возрастет до 38с.
Причина кроется в том, что в колонке t_2.fk_id_skew кроется 1 500 000 значений = 1 и 3 500 000 остальных. И при выполнении "PX SEND HASH" большая часть строк таблицы попадают в один поток для обработки, вместо того, чтобы равномерно распределиться.
Это хорошо видно в статистике выполнения. Для просмотра воспользуемся функцией "DBMS_SQLTUNE.REPORT_SQL_MONITOR".
Нас интересуют вкладки Parallel и Activity:

Рис.1 - Большую часть времени запрос выполнялся в один поток, остальные потоки его ждали.
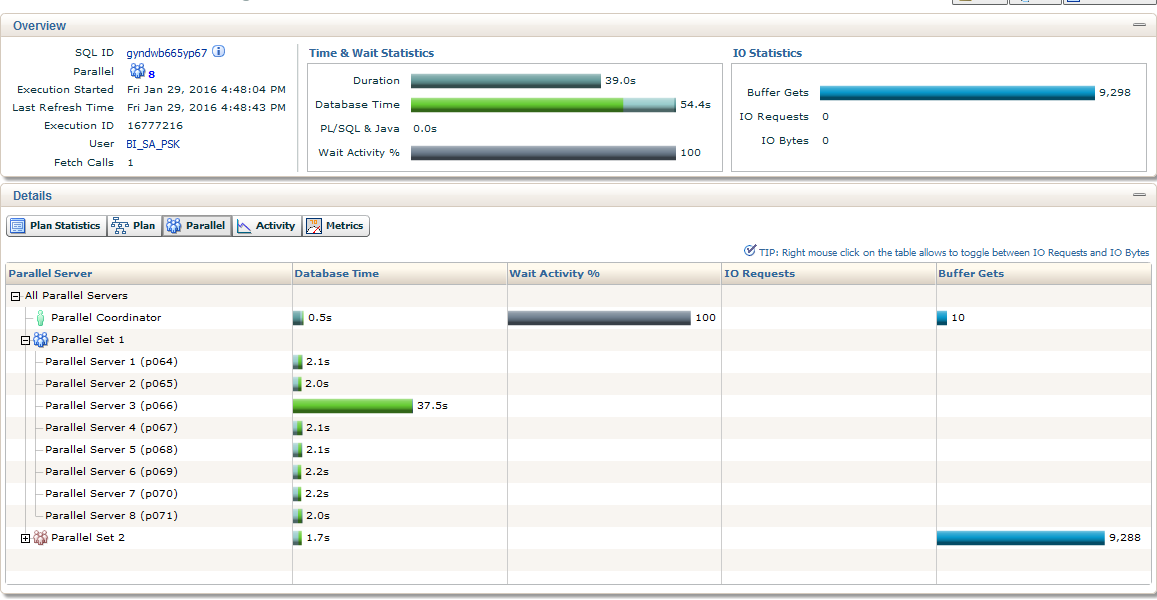
Рис. 2. - Это же подтверждается на вкладке PARALLEL: 37c от общего времени работал 1 поток.
Oracle поступает верно, т.к. нельзя же сделать join данных из разных диапазонов.
Для сравнения взгляните статистику выполнения для хорошо распараллеленого запроса (План 1) с условием без перекосов t_2.fk_id_uniform = t_1.id
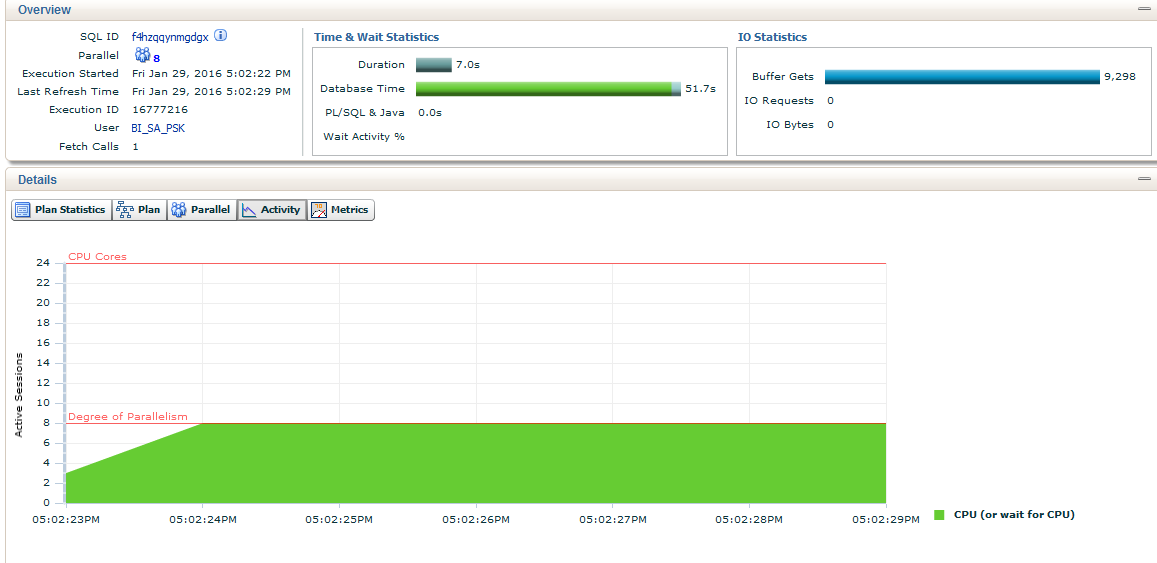
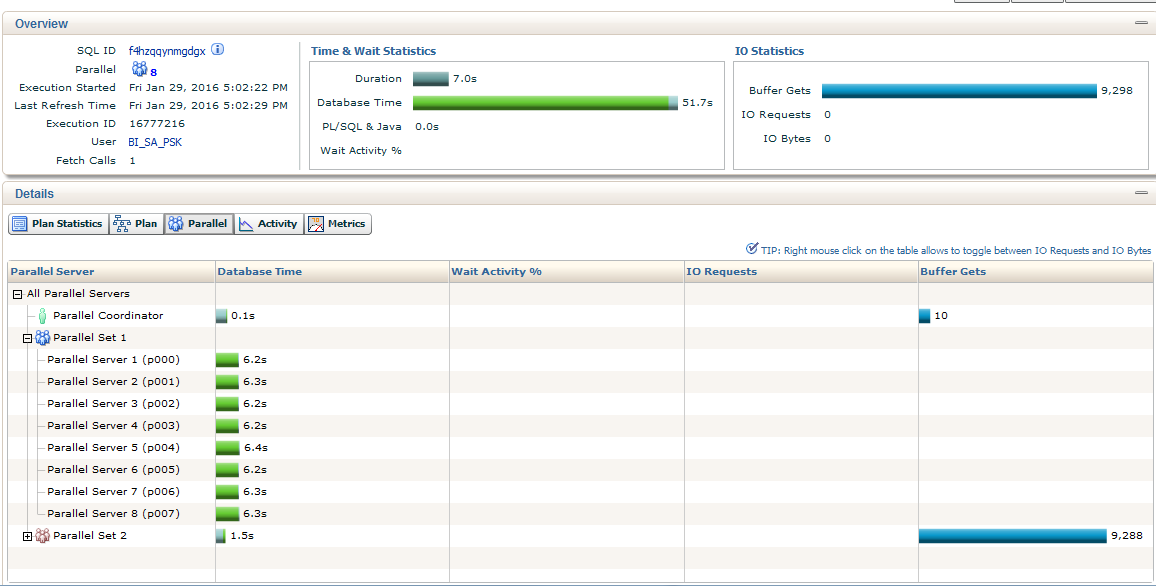
Рис. 3 и Рис. 4
Все выполнялось в 8 потоков и каждый поток равномерно обработал только свою равную часть.
Собственно решения этой проблемы из коробки в Oracle 11 нет. Гистограммы, как при анализе статистики не помогают, т.к. параллелятся данные по значениям в столбцах.
Есть обходные маневры ( http://allthingsoracle.com/parallel-execution-skew-addressing-skew-using-manual-rewrites/ ):
* Разбиваем запрос на UNION, где первая часть без перекошенного значения в параллели и второй union с перкошенным без параллели
* Через генерацию сурогатных уникальных ключей для перекошенного значения на основе косвенных показателей и соединение по новому ключу.
В этом случае данные по равномерному уникальному ключу будут удачно распараллелены.
Замечу, что в Oracle 12 эту проблему уже решили через гистограммы. В плане это отобразится как "PX SEND HYBRID HASH (SKEW)" (HYBRID HASH), т.е. Oracle сам сгенерировал сурогатные ключи для перекошенного значения и удачно смогу распараллелить. (подробней: http://allthingsoracle.com/parallel-execution-skew-12c-hybrid-hash-distribution-with-skew-detection/ )
3. Bloom filters
Не вдаваясь в механику создания битовых векторов bloom filter опишу преимущество их использования.
Пример запроса:
SELECT * FROM t1, t2 WHERE t1.id = t2.id AND t1.mod = 42
--------------------------------------------------------------------------
| Id | Operation | Name | TQ |IN-OUT| PQ Distrib |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | |
| 1 | PX COORDINATOR | | | | |
| 2 | PX SEND QC (RANDOM) | :TQ10002 | Q1,02 | P->S | QC (RAND) |
|* 3 | HASH JOIN BUFFERED | | Q1,02 | PCWP | |
| 4 | PX JOIN FILTER CREATE| :BF0000 | Q1,02 | PCWP | |
| 5 | PX RECEIVE | | Q1,02 | PCWP | |
| 6 | PX SEND HASH | :TQ10000 | Q1,00 | P->P | HASH |
| 7 | PX BLOCK ITERATOR | | Q1,00 | PCWC | |
|* 8 | TABLE ACCESS FULL| T1 | Q1,00 | PCWP | |
| 9 | PX RECEIVE | | Q1,02 | PCWP | |
| 10 | PX SEND HASH | :TQ10001 | Q1,01 | P->P | HASH |
| 11 | PX JOIN FILTER USE | :BF0000 | Q1,01 | PCWP | |
| 12 | PX BLOCK ITERATOR | | Q1,01 | PCWC | |
| 13 | TABLE ACCESS FULL| T2 | Q1,01 | PCWP | |
--------------------------------------------------------------------------
3 - access("T1"."ID"="T2"."ID")
8 - filter("T1"."MOD"=42)
1. На таблице T1 с фильтром "filter("T1"."MOD"=42)" создается bloom filter - PX JOIN FILTER CREATE2. Фильтр из п.1 применяется на таблицу T2 - PX JOIN FILTER USE
Тем самым ограничивая размер правой таблицы.
3. Отфильтрованная таблица T2 соединяется с HASH JOIN BUFFERED
Подробное описание bloom filter: Bloom filter
bloom filter хороши в:
* Параллельных запросах - уменьшается количество передаваемых данных между потоками за счет предфильтрации правой таблицы
* RAC системах - уменьшает число передаваемых по сети данных между нодами
* InMemory таблицах - осуществляя inmemory предфильтрацию таблицы и осуществление не inmemory join на быстро отфильтрованной правой таблице
4. Partition Wise
В целом похоже на предыдущий пункт, но фильтр накладывается на партиции правой таблицы, также уменьшая сканирования.
Дедектируется в плане по фразам:
* PART JOIN FILTER CREATE ( :BF0000 ) - создание фильтра на левой таблице
* Pstart| Pstop = :BF0000|:BF0000 - применение фильтра в операции чтения правой таблицы PCWC
with reg as (
select /*+ MATERIALIZE */ r.kd_reg, r.NM_reg, r.NM_TER, r.dimension_key
from dim_region r
where r.nm_otd = 'Фильтр левой таблицы'
and r.src_id = 2
)
select /*+ OPT_ESTIMATE(table bd MIN=1000000) LEADING(r1 bd) parallel(8) */
r1.NM_reg as nm_otd,
bd.sm_bal + bd.sm_bal_nds as sm_bal
from reg r1
join FCT_PROM_BAL_DT bd on bd.kd_reg = r1.kd_reg and bd.dim_region = r1.dimension_key
where bd.accounting_dt = to_date('01.12.2015', 'dd.mm.yyyy');
select * from table(dbms_xplan.display(format=>'ALLSTATS ALL ADVANCED'));
---------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
---------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000K| 103M| 155 (4)| 00:00:01 | | | | | |
| 1 | TEMP TABLE TRANSFORMATION | | | | | | | | | | |
| 2 | PX COORDINATOR | | | | | | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 4 | 304 | 2 (0)| 00:00:01 | | | Q1,00 | P->S | QC (RAND) |
| 4 | LOAD AS SELECT | SYS_TEMP_0FD9D750B_1C7D4113 | | | | | | | Q1,00 | PCWP | |
| 5 | PX BLOCK ITERATOR | | 4 | 304 | 2 (0)| 00:00:01 | | | Q1,00 | PCWC | |
|* 6 | TABLE ACCESS FULL | DIM_REGION | 4 | 304 | 2 (0)| 00:00:01 | | | Q1,00 | PCWP | |
| 7 | PX COORDINATOR | | | | | | | | | | |
| 8 | PX SEND QC (RANDOM) | :TQ20001 | 1000K| 103M| 153 (4)| 00:00:01 | | | Q2,01 | P->S | QC (RAND) |
|* 9 | HASH JOIN | | 1000K| 103M| 153 (4)| 00:00:01 | | | Q2,01 | PCWP | |
| 10 | PART JOIN FILTER CREATE| :BF0000 | 4 | 312 | 2 (0)| 00:00:01 | | | Q2,01 | PCWP | |
| 11 | PX RECEIVE | | 4 | 312 | 2 (0)| 00:00:01 | | | Q2,01 | PCWP | |
| 12 | PX SEND BROADCAST | :TQ20000 | 4 | 312 | 2 (0)| 00:00:01 | | | Q2,00 | P->P | BROADCAST |
| 13 | VIEW | | 4 | 312 | 2 (0)| 00:00:01 | | | Q2,00 | PCWP | |
| 14 | PX BLOCK ITERATOR | | 4 | 208 | 2 (0)| 00:00:01 | | | Q2,00 | PCWC | |
| 15 | TABLE ACCESS FULL | SYS_TEMP_0FD9D750B_1C7D4113 | 4 | 208 | 2 (0)| 00:00:01 | | | Q2,00 | PCWP | |
| 16 | PX BLOCK ITERATOR | | 1000K| 29M| 150 (3)| 00:00:01 |:BF0000|:BF0000| Q2,01 | PCWC | |
|* 17 | TABLE ACCESS FULL | FCT_PROM_BAL_DT | 1000K| 29M| 150 (3)| 00:00:01 | 4285 | 4403 | Q2,01 | PCWP | |
---------------------------------------------------------------------------------------------------------------------------------------------------------
Вторая часть по распределению данных в параллельных запросах
Комментариев нет:
Отправить комментарий