Показаны сообщения с ярлыком java. Показать все сообщения
Показаны сообщения с ярлыком java. Показать все сообщения
четверг, 21 ноября 2019 г.
воскресенье, 10 марта 2019 г.
четверг, 24 мая 2018 г.
LSM дерево: быстрый доступ по ключу в условиях интенсивной вставки
В условиях интенсивной вставки для быстрого доступа к данным обычные btree индексы не подходят.
Во многих базах (Bigtable, HBase, LevelDB, MongoDB, SQLite4, Tarantool, RocksDB, WiredTiger, Apache Cassandra, и InfluxDB ) используется LSM-дерево (Log-structured merge-tree — журнально-структурированное дерево со слиянием)
LSM дерево служит для хранения ключ-значения.
В данной статье рассмотрим двухуровневое дерево. Первый уровень целиком находится в памяти, вторая половина на диске.
Вставка идет всегда в первую часть в памяти, а поиск из всех частей. Когда размер данных в памяти превышает определенный порог, то она записывается на диск. После чего блоки на диске объединяются в один.
Рассмотрим алгоритм по частям:
1. Все записи в дереве маркируются порядковым номером glsn , при каждой вставке этот счетчик увеличивается
Структура для хранения ключа-значения и порядкового номера:
2. Структуры объядиняются в одну таблицу в памяти.
В моем алгоритме используется хэш таблица.
В реальности чаще всего используется отсортированная по ключу структура - это дает преимущества, что для поиска и слияния используется последовательное чтение, вместо рандомного.
3. Т.к. размер памяти ограничен, то при превышении определенного порога, данные должны быть скинуты на диск.
В моей реализации - это простой вариант без фоновых заданий и асинхронных вызовов
При достижении лимита будет фриз, т.к. таблица скидывается на диск.
В реальных системах используется упреждающая запись: данные на диск скидываются асинхронно и заранее, до достижения жесткого лимита памяти.
4. Получается, что половина всех данных у нас хранится в хэше в памяти, а остальное в виде файлов на диске.
Чтобы не перебирать все файлы на диске создается дополнительная индексная структура, которая будет хранить метаинформацию о файлах в памяти:
5. Управляющий объект всего дерева хранит ссылку на таблицу с данными в памяти и на мета-индексы данных на диске:
6. Когда все объекты описаны, давайте посмотрим как происходит добавление нового элемента.
Добавление всегда идет в таблицу в памяти, что гарантирует быструю вставку:
* Увеличиваем глобальный счетчик элементов LSMTree.glsn
* Если число элментов превысило порог, то таблица скидывается на диск и очищается
В реальности это конечно не число элементов, а объем в байтах.
* Создается новый элемент SSItem
* И доблавляется в хэш массив
Причем, если элемент до этого уже существовал, то он перезаписывается.
В реальности хранятся все записи, чтобы была возможность поддержки транзакционности.
* Кроме этого в индексе обновляются метаданные indx.add
7. С вставкой разобрались, теперь обратная операция - поиск элемента в дереве:
* Сперва мы проверяем наличие ключа в хэш таблице в памяти. Если элемент нашелся, то на этом все.
* Если элемента нет, то мы пробегамся по всем метаиндексам в поиске нашего ключа.
* проверяем, что ключ входит в диапазон indx.min_key - indx.max_key индекса
* И для полной точности проверяем наличие ключа в хэше ключей indx.keys.containsKey
* Если элемент нашелся, то это еще не конец, цикл продолжается, пока мы не переберем все индексы.
Т.к. ключ может добавляться несколько раз в разные промежутки времени.
* Из всех совпадений выбираем индекс с максимальным счетчиком вставки - это последнее изменение ключа
** Открываем нужный файл
В реальности, скорей всего, файы постоянно держатся открытыми для экономии времени.
** Следуя смещенями из индекса переходим к нужной точке файла file.seek
** И считываем значение file.read
8. Т.к. ключ может вставляться неограниченное число раз, то со временем он может находится в нескольких файлах на диске одновременно.
Также, если бы LSM дерево поддерживало транзакционность, то в файлах также хранились бы разные версии одного ключа (изменения или удаления).
Для оптимизации последующего поиска применяется операция слияния нескольких файлов в один:
* Сортируем индексы по убыванию lsn
* Последовательно считываем элементы из первого индекса и записываем в новый
* Если элемент уже присутствует в объединенном индексе, то он пропускается
* Создается новый единственный файл и индекс со всеми ключами и значениями
* Старые файлы и индексы удаляются
В реальности данные хранят в отсотированной структуре, что позволят выполнять слияние 2 отсортированных массивов в один за линейное время используя только быстрое последовательное чтение.
Полный код класса LSM дерева можно посмотреть на github
Во многих базах (Bigtable, HBase, LevelDB, MongoDB, SQLite4, Tarantool, RocksDB, WiredTiger, Apache Cassandra, и InfluxDB ) используется LSM-дерево (Log-structured merge-tree — журнально-структурированное дерево со слиянием)
LSM дерево служит для хранения ключ-значения.
В данной статье рассмотрим двухуровневое дерево. Первый уровень целиком находится в памяти, вторая половина на диске.
Вставка идет всегда в первую часть в памяти, а поиск из всех частей. Когда размер данных в памяти превышает определенный порог, то она записывается на диск. После чего блоки на диске объединяются в один.
Рассмотрим алгоритм по частям:
1. Все записи в дереве маркируются порядковым номером glsn , при каждой вставке этот счетчик увеличивается
Структура для хранения ключа-значения и порядкового номера:
//запись с ключ-значение
class SSItem {
Integer key;
String value;
//+ идентификатор последовательности вставки
Integer lsn;
SSItem(Integer key, String value, Integer lsn) {
this.key = key;
this.value = value;
this.lsn = lsn;
}
2. Структуры объядиняются в одну таблицу в памяти.
В моем алгоритме используется хэш таблица.
В реальности чаще всего используется отсортированная по ключу структура - это дает преимущества, что для поиска и слияния используется последовательное чтение, вместо рандомного.
class MemSSTable {
//из-за хэша нет поиска по диапазону
HashMap<Integer, SSItem> itms = new HashMap<Integer, SSItem>();
3. Т.к. размер памяти ограничен, то при превышении определенного порога, данные должны быть скинуты на диск.
В моей реализации - это простой вариант без фоновых заданий и асинхронных вызовов
При достижении лимита будет фриз, т.к. таблица скидывается на диск.
В реальных системах используется упреждающая запись: данные на диск скидываются асинхронно и заранее, до достижения жесткого лимита памяти.
void SaveToDisk() throws FileNotFoundException, UnsupportedEncodingException {
indx.path = "sstable_" + indx.max_lsn + ".dat";
PrintWriter writer = new PrintWriter(indx.path, "UTF-8");
Integer pad = 0;
//последовательно пишем 10 байт с длиной значения и само значение
for(Entry<Integer, SSItem> entry : itms.entrySet()) {
SSItem itm = entry.getValue();
String val = itm.get();
writer.print( val );
//регистрируем в индексе смещения в файле
indx.keys.put(itm.key, pad);
pad = pad + val.length();
}
writer.close();
LSMTree.indexes.add(indx);
} //SaveToDisk
4. Получается, что половина всех данных у нас хранится в хэше в памяти, а остальное в виде файлов на диске.
Чтобы не перебирать все файлы на диске создается дополнительная индексная структура, которая будет хранить метаинформацию о файлах в памяти:
//индекс над таблицей с даными
class SSTableIndex {
//метаданные:
//минимальный и максимальный ключи в таблице
Integer min_key;
Integer max_key;
//минимальный и максимальный порядковый lsn
Integer min_lsn;
Integer max_lsn;
//если таблица на диске, то путь до файла
String path;
//ключ - смещение ключа в файле
HashMap<Integer, Integer> keys = new HashMap<Integer, Integer>();
//добавить ключ в индекс
void add(Integer k) {
//также обновляем метаданные
max_lsn = LSMTree.glsn;
if(min_lsn == null) min_lsn = max_lsn;
if(min_key == null || k < min_key) min_key = k;
if(max_key == null || k > max_key) max_key = k;
//добавление идет в память в хэш таблицу, на первом этапе смещения в файле нет
keys.put(k, 0);
}
5. Управляющий объект всего дерева хранит ссылку на таблицу с данными в памяти и на мета-индексы данных на диске:
public class LSMTree {
static int glsn = 0;
//максимальный размер, после которого таблица должна быть скинута на диск
//для упрощения алгоритма = числу записей, а не размеру в байтах
final static int max_sstable_size = 10;
//текущая таблица в памяти, куда вставляем данные
MemSSTable MemTable;
//все индексы, даже для таблиц на диске, хранятся в памяти
static LinkedList<SSTableIndex> indexes = new LinkedList<SSTableIndex>();
6. Когда все объекты описаны, давайте посмотрим как происходит добавление нового элемента.
Добавление всегда идет в таблицу в памяти, что гарантирует быструю вставку:
public class LSMTree {
//....
//добавить запись
public void add(Integer k, String v) {
MemTable.add(k, v);
}
Подробней логика добавления в таблицу в памяти:* Увеличиваем глобальный счетчик элементов LSMTree.glsn
* Если число элментов превысило порог, то таблица скидывается на диск и очищается
В реальности это конечно не число элементов, а объем в байтах.
* Создается новый элемент SSItem
* И доблавляется в хэш массив
Причем, если элемент до этого уже существовал, то он перезаписывается.
В реальности хранятся все записи, чтобы была возможность поддержки транзакционности.
* Кроме этого в индексе обновляются метаданные indx.add
class MemSSTable {
//.....
//добавить новый элемент
void add(Integer k, String v) {
//увеличиваем глобальный счетчик операций glsn
LSMTree.glsn++;
//если размер превышает,
if(itms.size() >= LSMTree.max_sstable_size) {
try {
//то сохраняем таблицу на диск
//в реальных движках используется упреждающая фоновая запись
//когда папять заполнена на N% (n<100), то данные скидываются на диск заранее, чтобы избежать фриза при сбросе памяти и записи на диск
SaveToDisk();
} catch (FileNotFoundException | UnsupportedEncodingException e) {
e.printStackTrace();
return;
}
//очищаем данные под новые значения
indx = new SSTableIndex();
itms = new HashMap<Integer, SSItem>();
}
//обновляем медаданные в индексе
indx.add(k);
SSItem itm = new SSItem(k, v, indx.max_lsn);
//в моей реализации, при повторе ключ перезаписывается
//т.е. транзакционность и многоверсионность тут не поддерживается
itms.put(k, itm);
} //add
Если после вставки нового элемента старые данные оказались на диске, то в метаданных индекса прописывается ссылка на точное смещение в файле:
class SSTableIndex {
//...
//если таблица на диске, то путь до файла
String path;
//ключ - смещение
HashMap<Integer, Integer> keys = new HashMap<Integer, Integer>();
7. С вставкой разобрались, теперь обратная операция - поиск элемента в дереве:
* Сперва мы проверяем наличие ключа в хэш таблице в памяти. Если элемент нашелся, то на этом все.
* Если элемента нет, то мы пробегамся по всем метаиндексам в поиске нашего ключа.
* проверяем, что ключ входит в диапазон indx.min_key - indx.max_key индекса
* И для полной точности проверяем наличие ключа в хэше ключей indx.keys.containsKey
* Если элемент нашелся, то это еще не конец, цикл продолжается, пока мы не переберем все индексы.
Т.к. ключ может добавляться несколько раз в разные промежутки времени.
* Из всех совпадений выбираем индекс с максимальным счетчиком вставки - это последнее изменение ключа
public class LSMTree {
//.....
//получить значение по ключу
String getKey(Integer key) {
//сперва смотрим в памяти
String val = MemTable.getKey(key);
if(val == null) {
SSTableIndex indx_with_max_lsn = null;
//потом таблицу по индексам, которая содержит наш ключ
//если содержится в нескольких, то берем с максимальным lsn, т.к. это последнее изменение
for (SSTableIndex indx : indexes) {
Integer max_lsn = 0;
if(key >= indx.min_key && key <= indx.max_key && max_lsn < indx.max_lsn ) {
if(indx.keys.containsKey(key)) {
max_lsn = indx.max_lsn;
indx_with_max_lsn = indx;
}
}
}
//читаем из таблицы с диска
if(indx_with_max_lsn != null) {
try {
return indx_with_max_lsn.getByPath(key);
} catch (IOException e) {
e.printStackTrace();
}
}
}
return val;
}
* Определим нужный индекс обращаемся по нему к таблице на диске:** Открываем нужный файл
В реальности, скорей всего, файы постоянно держатся открытыми для экономии времени.
** Следуя смещенями из индекса переходим к нужной точке файла file.seek
** И считываем значение file.read
class SSTableIndex {
//...
//получить значение ключа из открытого файла
String getByPath(Integer key, RandomAccessFile file) throws IOException {
//получаем смещение в файле для ключа из индекса
Integer offset = keys.get(key);
//смещаемся в файле
file.seek(offset);
//резервируем 10 байт под переменную с длинной значения
byte[] lenb = new byte[10];
file.read(lenb, 0, 10);
Integer len = Integer.parseInt(new String(lenb, StandardCharsets.UTF_8));
file.seek(offset + 10);
//считываем значение
byte[] valb = new byte[len];
file.read(valb, 0, len);
return new String(valb, StandardCharsets.UTF_8);
} //getByPath
//получить значение ключа с диска
String getByPath(Integer key) throws IOException {
if(!keys.containsKey(key)) return null;
RandomAccessFile file = new RandomAccessFile(path, "r");
String val = getByPath(key, file);
file.close();
return val;
}
8. Т.к. ключ может вставляться неограниченное число раз, то со временем он может находится в нескольких файлах на диске одновременно.
Также, если бы LSM дерево поддерживало транзакционность, то в файлах также хранились бы разные версии одного ключа (изменения или удаления).
Для оптимизации последующего поиска применяется операция слияния нескольких файлов в один:
* Сортируем индексы по убыванию lsn
* Последовательно считываем элементы из первого индекса и записываем в новый
* Если элемент уже присутствует в объединенном индексе, то он пропускается
* Создается новый единственный файл и индекс со всеми ключами и значениями
* Старые файлы и индексы удаляются
public class LSMTree {
//....
//объединить несколько таблиц на диске в 1 большую
void merge() throws IOException {
Integer min_key = null;
Integer max_key = null;
Integer min_lsn = null;
Integer max_lsn = null;
//сортируем таблицы по убыванию lsn
//чтобы вначале были самые свежие ключи
Collections.sort(indexes, new Comparator<SSTableIndex>() {
@Override
public int compare(SSTableIndex o1, SSTableIndex o2) {
if(o1.max_lsn > o2.max_lsn) {
return -1;
} else if(o1.max_lsn < o2.max_lsn) {
return 1;
}
return 0;
}
});
SSTableIndex merge_indx = new SSTableIndex();
Integer pad = 0;
merge_indx.path = "sstable_merge.dat";
PrintWriter writer = new PrintWriter(merge_indx.path, "UTF-8");
//пробегаемся по всем индексам, чтобы слить в 1
for (SSTableIndex indx : indexes) {
if(min_lsn == null || indx.min_lsn < min_lsn) min_lsn = indx.min_lsn;
if(min_key == null || indx.min_key < min_key) min_key = indx.min_key;
if(max_key == null || indx.max_key > max_key) max_key = indx.max_key;
if(max_lsn == null || indx.max_lsn > max_lsn) max_lsn = indx.max_lsn;
RandomAccessFile file = new RandomAccessFile(indx.path, "r");
//т.к. данные в таблицах не упорядочены, это приводит к рандомным чтениям с диска
//в реальности делают упорядочнный по ключу массив, чтобы делать быстрые последовательные чтения
for(Entry<Integer, Integer> entry : indx.keys.entrySet()) {
//оставляем запись только с максимальным lsn
Integer key = entry.getKey();
if(!merge_indx.keys.containsKey(key)) {
String val = indx.getByPath(key, file);
SSItem itm = new SSItem(key, val, 0);
String itmval = itm.get();
writer.print( itmval );
merge_indx.keys.put(key, pad);
pad = pad + itmval.length();
}
}
//записываем и удаляем старые файлы
file.close();
//delete
File fd = new File(indx.path);
fd.delete();
}
merge_indx.min_lsn = min_lsn;
merge_indx.min_key = min_key;
merge_indx.max_key = max_key;
merge_indx.max_lsn = max_lsn;
writer.close();
//переименовываем к обычному имени
File fd = new File(merge_indx.path);
merge_indx.path = "sstable_" + merge_indx.max_lsn + ".dat";
File fdn = new File(merge_indx.path);
fd.renameTo(fdn);
indexes = new LinkedList<SSTableIndex>();
indexes.add(merge_indx);
} //merge
В моей реализации используется хэш массив, что дает большое число случайных чтений с диска.В реальности данные хранят в отсотированной структуре, что позволят выполнять слияние 2 отсортированных массивов в один за линейное время используя только быстрое последовательное чтение.
Полный код класса LSM дерева можно посмотреть на github
пятница, 5 января 2018 г.
Hive: авторизация и аутентификация
Сборка Cloudera Hadoop не содержит никаких настроек авторизации и аутентификации, что конечно плохо, т.к. не дает возможности разделить права среди пользователей.
Опишу один из вариантов настройки авторизации и аутентификации.
2. Создаем пользователя в hive
3. Создаем java класс, через который будет происходить проверка пользователя:
user1;passwd
4. Компилируем класс в объект и собираем jar файл:
компилировать нужно именно той java под которой работает hadoop:
5. Включаем CUSTOM аутентификацию в настройках Cloudera Manager:
прописываем наш аутентификатор в настройках:
* Ищем все настройки по паттерну "hive-site.xml" в настройках Cloudera.
Делать нужно именно через cloudera, а не напрямую в файле "hive-site.xml", т.к. менеджер переписывает файл из памяти процесса.

Нажимаем view as xml и во всех окнах и вводим
Также ставим флажки suppress parameter validation
Иначе настройки не попадут в итоговый XML файл
* Для работы также нужна включенная опция hive.server2.enable.doAs = true
Она означает, что все запросы будут идти из под пользователя, который прошел аутентификацию.
5. Задаем путь до кастомной папки с jar файлами:
Настройка: «HIVE_AUX_JARS_PATH»
Значение «/u01/jar»,
Также ставим suppress parameter validation

6. Все готово, перезапускам HIVE из консоли Cloudera
7. Теперь при аутентификации нужно указывать способ:

После того как все настроили, мы уверены, что пользователь прошел аутентификацию.
Войти без пароля больше не получится.
Дальше настраиваем авторизацию - выдачу прав пользователям на конкретные объекты.
Проще всего это сделать через расширенные права linux:
1. Включаем ACL права через Cloudera Manager
настройка "dfs.namenode.acls.enabled" = true

2. После этого можно распределять права на папки:
Сброс всех прав:
Даем пользователю user1 права на создание таблиц в своей схеме
Как победить эту проблему я не понял.
Так же стоит не забывать, что таким образом мы защитили только HIVE, возможность читать данные через HDFS по прежнему остались.
(Как читать данные из HDFS и HIVE через java можно посмотреть в моем github: https://github.com/pihel/java/blob/master/bigdata/Hdfs2Hive.java )
Чтобы закрыть доступ чтения через HDFS мы используем закрытие всех портов на сервере, кроме 10000 , который используется службой HIVE.
Опишу один из вариантов настройки авторизации и аутентификации.
Custom аутентификация:
1. Создаем linux пользователя на сервере hadoop:sudo useradd user1 #создаем домашнюю директорию в hdfs sudo -u hdfs hadoop fs -mkdir /user/user1 #задаем пользователя владельцем sudo -u hdfs hadoop fs -chown user1 /user/user1 sudo passwd user1 #лочим пользователя в linux sudo passwd -l user1
2. Создаем пользователя в hive
sudo -u hive hive CREATE SCHEMA user1 LOCATION "/user/user1";
3. Создаем java класс, через который будет происходить проверка пользователя:
package hive.lenta;
import java.util.Hashtable;
import javax.security.sasl.AuthenticationException;
import org.apache.hive.service.auth.PasswdAuthenticationProvider;
import java.io.*;
public class LentaAuthenticator implements PasswdAuthenticationProvider {
Hashtable<String, String> store = null;
public LentaAuthenticator () {
store = new Hashtable<String, String>();
try {
readPwd();
} catch (IOException e) {
e.printStackTrace();
}
} //LentaAuthenticator
public void readPwd () throws IOException {
BufferedReader br = new BufferedReader(new FileReader("/u01/jar/pwd.ini"));
String line;
while ((line = br.readLine()) != null) {
String login[] = line.split(";");
if(login.length == 2) {
store.put(login[0].trim(), login[1].trim());
}
}
br.close();
} //readPwd
@Override
public void Authenticate(String user, String password)
throws AuthenticationException {
String storedPasswd = store.get(user);
if (storedPasswd != null && storedPasswd.equals(password))
return;
throw new AuthenticationException("LentaAuthenticator: Error validating user");
}
}
В файле /u01/jar/pwd.ini лежит логин и пароль, разделенные точкой с запятой:user1;passwd
4. Компилируем класс в объект и собираем jar файл:
компилировать нужно именно той java под которой работает hadoop:
/usr/java/jdk1.7.0_67-cloudera/bin/javac -classpath /u01/cloudera/parcels/CDH-5.11.1-1.cdh5.11.1.p0.4/lib/hive/lib/hive-service.jar -d /home/askahin/auth /home/askahin/auth/LentaAuthenticator.java /usr/java/jdk1.7.0_67-cloudera/bin/jar -cf /home/askahin/auth/jar/lentauth.jar ./hive sudo cp jar/lentauth.jar /u01/cloudera/parcels/CDH-5.11.1-1.cdh5.11.1.p0.4/lib/hive/lib/ sudo chmod 777 /u01/cloudera/parcels/CDH-5.11.1-1.cdh5.11.1.p0.4/lib/hive/lib/lentauth.jar sudo cp jar/lentauth.jar /u01/jar/lentauth.jar sudo chmod 777 /u01/jar/lentauth.jar
5. Включаем CUSTOM аутентификацию в настройках Cloudera Manager:
прописываем наш аутентификатор в настройках:
* Ищем все настройки по паттерну "hive-site.xml" в настройках Cloudera.
Делать нужно именно через cloudera, а не напрямую в файле "hive-site.xml", т.к. менеджер переписывает файл из памяти процесса.
Нажимаем view as xml и во всех окнах и вводим
<property>
<name>hive.server2.authentication</name>
<value>CUSTOM</value>
</property>
<property>
<name>hive.server2.custom.authentication.class</name>
<value>hive.lenta.LentaAuthenticator</value>
</property>
Также ставим флажки suppress parameter validation
Иначе настройки не попадут в итоговый XML файл
* Для работы также нужна включенная опция hive.server2.enable.doAs = true
Она означает, что все запросы будут идти из под пользователя, который прошел аутентификацию.
5. Задаем путь до кастомной папки с jar файлами:
Настройка: «HIVE_AUX_JARS_PATH»
Значение «/u01/jar»,
Также ставим suppress parameter validation
6. Все готово, перезапускам HIVE из консоли Cloudera
7. Теперь при аутентификации нужно указывать способ:
AuthMech=3
После того как все настроили, мы уверены, что пользователь прошел аутентификацию.
Войти без пароля больше не получится.
Дальше настраиваем авторизацию - выдачу прав пользователям на конкретные объекты.
Проще всего это сделать через расширенные права linux:
ACL авторизация
1. Включаем ACL права через Cloudera Manager
настройка "dfs.namenode.acls.enabled" = true
2. После этого можно распределять права на папки:
Сброс всех прав:
sudo -u hdfs hdfs dfs -setfacl -R -b /
Даем пользователю user1 права на создание таблиц в своей схеме
sudo -u hdfs hdfs dfs -setfacl -R --set user::rwx,user:hadoop:rwx,user:hive:rwx,user:user1:rwx,group::r-x,other::--- /user/user1к остальному хранилищу hive даем права только на чтение:
sudo -u hdfs hdfs dfs -setfacl -R --set user::rwx,user:hadoop:rwx,user:hive:rwx,user:user1:r-x,group::r-x,other::--- /user/hive/warehouseк какой-то из таблиц закрываем доступ:
sudo -u hdfs hdfs dfs -setfacl -R --set user::rwx,user:hadoop:rwx,user:hive:rwx,user:user1:---,group::r-x,other::--- /user/hive/warehouse/table1Один минус у ACL - это остается возможность выполнить DROP table, даже если нет прав доступа на чтение или запись.
Как победить эту проблему я не понял.
Так же стоит не забывать, что таким образом мы защитили только HIVE, возможность читать данные через HDFS по прежнему остались.
(Как читать данные из HDFS и HIVE через java можно посмотреть в моем github: https://github.com/pihel/java/blob/master/bigdata/Hdfs2Hive.java )
Чтобы закрыть доступ чтения через HDFS мы используем закрытие всех портов на сервере, кроме 10000 , который используется службой HIVE.
вторник, 15 августа 2017 г.
HIVE: Своя быстрая функция замен встроенной
Один из вариантов ускорить HIVEQL запрос - это переписать встроенную аналитическую функцию на свой упрощенный вариант.
К примеру функция ROW_NUMBER(OVER PARTITION BY c1 ORDER BY c2) имеет достаточно сложную реализацию (github) только для того чтобы посчитать номер строки в группе.
Пример запроса с row_number:
create table tmp_table stored as orc as select v.material, v.client_id, row_number() over (partition by v.client_id order by v.clientsum desc, v.checkcount desc) as rn from pos_rec_itm_tst v;
Можно реализовать значительно упрощенную версию подсчета номера строки в группе.
На вход функции Rank.evaluate подаем значение группы key (то что было в partition by) и инкрементируем значение счетчика counter.
Если приходит новая группа, то счетчик сбрасывается на 0, а в переменную группы "this.last_key" записывается значение новой группы:
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public final class Rank extends UDF{
private int counter;
private String last_key;
public int evaluate(final String key){
if ( !key.equals(this.last_key) ) {
this.counter = 0;
this.last_key = key;
}
return (++this.counter);
}
}
Понятно, что для правильной работы этой функции набор данных нужно предварительно отсортировать по группе партицирования "partition by", а потом по остальным полям "order by".Пример запроса с собственной функцией:
create table tmp_table stored as orc as select v.material, v.client_id, myrank(v.client_id) as rn from ( SELECT client_id, clientsum, checkcount, material FROM pos_rec_itm_tst DISTRIBUTE BY client_id SORT BY clientsum desc, checkcount desc ) v;Дополнительно сортировку в HIVE можно ускорить, если распараллелить мапперы по полю партицирования "partition by", а внутри этих групп сортировать по полям из "order by".
За счет параллельности мы опять же ускорим сортировку.
Чтобы создать такую функцию в HIVE нужно скомпилировать ее из java исходников:
$> /путь_до_java_который_используется_в_hive/bin/javac -classpath /путь_до_hive/lib/hive/lib/hive-serde-1.7.jar:/путь_до_hive/lib/hive/lib/hive-exec.jar:/путь_до_hadoop/lib/hadoop/client-0.20/hadoop-core.jar -d /путь_куда_компилим /путь_до_программы.java $> /путь_до_java_который_используется_в_hive/bin/jar -cf название_jar_программы.jar com/example/hive/udf/название_класса.class
запускаем hive и регистрируем наш jar , как функцию с произвольным названием:
hive> add jar Rank.jar; hive> create temporary function myrank as 'com.example.hive.udf.Rank';
Такое небольшое изменение ускорит выполнение запроса на 10-20%.
воскресенье, 26 марта 2017 г.
Решение bigdata задач на Hadoop mapreduce
Hadoop
Набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов.Ссылка на установку: http://www.cloudera.com/content/www/en-us/downloads.html
Hadoop состоит из 2 основных частей hdfs и map reduce. Рассмотрим подробней.
Hdfs
- распределенная файловая система. Это значит, что данные файла распределены по множеству серверов.* hdfs лучше работает с небольшим числом больших файлов/блоков
* один раз записали, много раз считали
* можно только целиком считать, целиком очистить или дописать в конец (нельзя с середины)
* файлы бьются на блоки split (к примеру 64мб)
** размер блока выбирается так, чтобы нивилировать время передачи блока по сети (если сеть быстрая, то блок можно поменьше, если медленная, то больше)
* все блоки реплицируются с фактором 3 поумолчанию (хранятся в 3 копиях на разных серверах)
** это обеспечивает высокую пропускную способность, но не скорость реакции
Hdfs java api
Пример программы копирующей один файл в другой:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.InputStream;
Path source_path = new Path(args[0]);
Path target_path = new Path(args[1]);
Configuration conf = new Configuration();
FileSystem source_fs = FileSystem.get(source_path.toUri(), conf);
FileSystem target_fs = FileSystem.get(target_path.toUri(), conf);
//доступ к нескольким файлам по маскам
//FileStatus [] files = fs.globStatus(glob);
//?, *, [abc], [^a], {ab, cd}
FSDataOutputStream output = target_fs.create(target_path);
InputStream input = null;
try{
input = source_fs.open(source_path);
IOUtils.copyBytes(input, output, conf);
} finally {
IOUtils.closeStream(input);
IOUtils.closeStream(output);
}
Парадигма map reduce
1. input file: split 1 + split 2 + split 3 (блоки файла). Каждый сплит хранится на своем сервере кластера.2. mapper:
* на каждый split N создается worker для обработки
* worker выполяется на сервере, где находится блок
* workerы не могут обмениваются между собой данными
** т.е. mapper подходит для независимых данных, которые легко побить на части.
зависимые данные (типа архива zip) нельзя побить на части в mapper:
все блоки (split) будут переданы в один mapper
* в случае ошибки процесс рестратует на другой копии блока hdfs
* combine - (необязательный шаг) - reducer внутри mappera агрегирующие данные в меньшее число данных (ключ менять нельзя)
** агрегирует только данные одного маппера
* partition - (необязательный шаг) - определение куда отправится ключ (поумолчанию hash(k) mod N , где N - число reducer )
3. результат mapper записывается в виде ключ значение {k->v} в циклический буфер в памяти, конец списка пишется на локальный диск сервера с worker
** это сделано в целях производительности, чтобы не реплицировать
** но в случае ошибки, данные нельзя будет восстановить и потребует рестартовать mapper
4. данные из {k->v} расходятся на сервера reduccer на основе ключа.
Т.е. данные с разных mapperов но с одним key попадут в один reducer
5. Результат reducer складываются в hdfs. Число файлов = число reducer
Hadoop streaming
Инструмент для быстрого прототипирования map reduce задач.можно писать python программы заготовки, общение маппера с редусером проиходит чреез stdin/out.
Данные передаются как текст разделенный табом
word count
#!/usr/bin/python
import sys
for line in sys.stdin:
for token in line.strip().split(" "):
if token: print(token + '\t1')
#!/usr/bin/python
import sys
(lastKey, sum)=(None, 0)
for line in sys.stdin:
(key, value) = line.strip().split("\t")
if lastKey and lastKey != key:
print (lastKey + '\t' + str(sum))
(lastKey, sum) = (key, int(value))
else:
(lastKey, sum) = (key, sum + int(value))
if lastKey:
print (lastKey + '\t' + str(sum))
Запуск:
hadoop jar $HADOOP_HOME/hadoop/hadoop-streaming.jar \ -D mapred.job.name="WordCount Job via Streaming" \ -files countMap.py, countReduce.py \ -input text.txt \ -output /tmp/wordCount/ \ -mapper countMap.py \ -combiner countReduce.py \ -reducer countReduce.py
Java source code example
Программа подсчитывающая число слов в hdfs файле.word count
public class WordCountJob extends Configured implements Tool {
static public class WordCountMapper extends Mapper < LongWritable, Text, Text, IntWritable > {
private final static IntWritable one = new IntWritable(1);
private final Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//разбиваем строку (key) на слова и передаем пару: слово, 1
StringTokenizertokenizer = new StringTokenizer(value.toString());
while (tokenizer.hasMoreTokens()) {
text.set(tokenizer.nextToken());
context.write(text, one);
}
} //map
} //WordCountMapper
static public class WordCountReducer extends Reducer < Text, IntWritable, Text, IntWritable > {
@Override
protected void reduce(Text key, Iterable < IntWritable > values, Context context) throws IOException, InterruptedException {
//в редусер приходят все единицы от одного слова
intsum = 0;
for (IntWritable value: values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
} //reduce
} //WordCountReducer
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "WordCount");
//класс обработчик
job.setJarByClass(getClass());
//путь до файла
TextInputFormat.addInputPath(job, new Path(args[0]));
//формат входных данных (можно отнаследовать и сделать собственный)
job.setInputFormatClass(TextInputFormat.class);
//классы мапперов, редусееров, комбайнеров и т.д.
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setCombinerClass(WordCountReducer.class);
//выходной файл
TextOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
} //run
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run( new WordCountJob(), args);
System.exit(exitCode);
} //main
} //WordCountJob
Такая программа будет тратить все время на передачу данных от маппера к редусеру.
Её можно усовершенствовать несколькими способами:
* Сделать комбайнер - чтобы данные из одного маппера были сагрегированы там.
- не обязательно вызывается
+/- агрегирует данные только одного вызова маппера (одной строки)
* хэш аггегировать внутри маппера:
+ обязательно выполнится
+/- агрегирует данные только одного вызова маппера (одной строки)
- нужно следить за размером хэш массива
* хэш массив сверху маппера, а внутри маппера обрабатывать
+ обязательно выполнится
+ агрегирует все вызовы маппера (сплита)
- нужно следить за размером хэш массива
Sql операции
Разность (minus) и другое по аналогии
// на вход подаются элементы из двух множеств A и B
class Mapper
method Map(rowkey key, value t)
Emit(value t, string t.SetName) // t.SetName либо ‘A‘ либо ‘B'
class Reducer
// массив n может быть [‘A'], [‘B'], [‘A' ‘B‘] или [‘B', ‘A']
method Reduce(value t, array n)
if n.size() = 1 and n[1] = 'A'
Emit(value t, null)
* hash join
class Mapper
method Initialize
H = new AssociativeArray : join_key -> tuple from A //хэшируем меньшую таблицу целиком в память
A = load()
for all [ join_key k, tuple [a1, a2,...] ] in A
H{k} = H{k}.append( [a1, a2,...] )
method Map(join_key k, tuple B)
for all tuple a in H{k} //ищем в A соответствие ключа из B
Emit(null, tuple [k a B] ) //если нашли, то записываем
Операции на графах
оптимальное представление в виде списка смежности, т.к. матрица смежности занимает слишком много места* поиск кратчайшего пути
** обычный алгоритм - дейкстра
** поиск в ширину (bfs)
на невзвешенном графе (нет связей назад):
- Останавливаемся, как только расстояния до каждой вершины стало известно
- Останавливаемся, когда пройдет число итераций, равное диаметру графа
на взвешенном графе (есть обратные связи):
- Останавливаемся, после того, как расстояния перестают меняться
* PR = a (1/N) + (1-a)* SUM( PR(i) / C(i) )
** N - начальное число точек в графе
** C - число исходящих точек
** a - вероятность случайного перехода
** pr решается только приблизительно:
- останавливаем, когда значения перестают меняться
- фиксированное число итерации
- когда изменение значение меньше определенного числа
* проблемы
** необходимость передавать весь граф между всеми задачами
** итеративный режим, т.е. переход на следующий этап, когда все параллельные задачи выполнятся
* оптимизации:
** inmemory combining - агрегируем сообщения в общем массиве
** партицирование - смежные точки оказались на одном маппере
** структуру графа читать из hdfs, а не передавать + партицирование
Высокоуровневые языки поверх hdfs или hadoop:
Pig
высокоуровневый язык + компилятор в mapreduceиспользуется для быстрого написания типовых map-reduce задач
основные составляющие:
* field - поле
* tuple - кортеж (1, "a", 2)
* bag - коллекция кортежей {(), ()}
** коллекции могут содержать разное кол-во полей в кортеже (также они могут быть разных типов)
word count:
input_lines = LOAD 'file-with-text' AS (line:chararray); words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word; filtered_words = FILTER words BY word MATCHES '\\w+'; word_groups = GROUP filtered_words BY word; word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word; ordered_word_count = ORDER word_count BY count DESC; STORE ordered_word_count INTO ‘number-of-words-file';
join
//Загрузить записи в bag #1
posts = LOAD 'data/user-posts.txt' USING PigStorage(',') AS (user:chararray,post:chararray,date:long);
//Загрузить записи в bag #2
likes = LOAD 'data/user-likes.txt' USING PigStorage(',') AS (user:chararray,likes:int,date:long);
userInfo = JOIN posts BY user, likes BY user;
DUMP userInfo;
Hive
sql подобный язык hivesql поверх hadoopосновные составляющие - как в бд
метаданные могут храниться в mysql /derby
* создание таблицы
hive> CREATE TABLE posts (user STRING, post STRING, time BIGINT) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ',' > STORED AS TEXTFILE;
* при нарушении схемы ошибки не будет, вставится NULL
join
hive> INSERT OVERWRITE TABLE posts_likes > SELECT p.user, p.post, l.count > FROM posts p JOIN likes l ON (p.user = l.user);
word count
CREATE TABLE docs (line STRING); LOAD DATA INPATH 'docs' OVERWRITE INTO TABLE docs; CREATE TABLE word_counts AS SELECT word, count(1) AS count FROM (SELECT explode(split(line, '\s')) AS word FROM docs) w GROUP BY word ORDER BY word;
Nosql
* Масштабирование:** мастер-слейв: распределение нагрузки cpu, io остается общим
** шардинг: деление данных таблицы по серверам: распределение io, cpu Общее
* cap theorem - достигается только 2 из 3
** consistency - непротиворечивость
Чаще всего жертвует строгой целостностью в текущий момент, на целостность в конечном счете
** aviability - доступность
** partioning - разделение данных на части
* типы:
** ключ-значение
** колоночная
** документоориентировання
** графовая
Hbase
- поколоночная база** строки в таблицах шардируются на сервера
*** строки хранятся в отстортированном виде, чтобы можно было искать по серверам
*** список шардов хранится в HMaster
через него определяется сервер для чтений, а дальше чтение идет уже напряму с него миную hmaster
! возможная точка отказа
** столбцы объединяются в column family
*** каждая такая группа сохраняется также в отдельный файл
*** для всей группы задается степень сжатия и другие физические настройки
** изменение/удаление происходит через вставку нового значения в колонку с TS
*** при select выбираются последние 3 изменения (если в колонке не было изменений, то берется предыдущая максимальная версия)
** промежуточные данные хранятся в memstore сервера и логе изменений
*** периодически данные из памяти скидываются на hdfs
** hfile - мапится в файл hdfs, который также splitit'ится на разные сервера
** сжатие файлов хранилища:
*** объединение файлов CF в один
*** очистка от удаленных записей
Массовость - деление данных на сервера по:
* по семейству колонок
* по диапазону ключей
* по версии строки
* сам файл разбивается в hdfs на сплиты
Cassandra
отличия:** есть sql, а не только java api
** CF имеют иерархичность и могут также объединяться в группы по какомуто признаку
** настраевая consistency от самой строгой - ожидание отклика всех серверов, то записи без проверок
** нет единой точки отказа hmaster, данные делятся по диапазону
** но усложняет деление и поиск данных
* greenplum - классическая колоночная бд, с шардирование данных на основе pgsql
** есть поддержка sql
Spark
Альтернативный вариант реализации hadoop.* Преимущества перед hadoop:
1. Необязательно сохранять промежуточные результаты в HDFS при итеративной разработке. Данные можно хранить в памяти.
2. Необязательно чередовать map-reduce, можно делать несколько reducer подряд
3. Операции в памяти (вкллючая синхронизацию между серверами), а не через hdfs
4. Возможность загрузить данные в распределенную память, а потом делать обработку (каждому mapper уже не надо считывать данные из hdfs)
* В основе может лежать любой вид хранилища данных
* Архитектура, как в hadoop: name node (driver) + worker
* Основная составляющая вещь - RDD:
** объект партицируется
** каждая партиция имеет произвольное хранение: память, диск, hdfs и т.д.
*** Для хранения данных в памяти используется LRU буфер.
Старые, редко используемые данны вытесняются в медленное хранилище
** объект неизменяем (изменение создает новый объект)
** rdd распределена по серверам
* Программа состоит из однонаправленного графа операций без циклов
Виды зависимостей в графе:
** Narrow (узкая) - переход 1 партииции в 1 другую
** wide (широкая) - переход 1 (N) партиций в N (1)
* Восстановление в случае падения:
- нет репликации как в hdfs
+ для воостановления используется перезапуск
** если потерялись данные из одной партиции в Narrow связи, то восстанавливается только она из предыдущей партиции
** если в wide то перезапускаются все партиции (т.к. связ не 1 к 1).
Результат wide поумолчанию сохраняется на диск.
** Если есть шанс потерять данные, а цепочка длинная, то лучше самим самостоятельно сохранять промежуточные результаты на диск.
* Типы операции состоят из:
** Трансформация - не запускают работу
map, filer, group, union, join ....
** Действий - запускают работу (все трансформации в графе до этого графа)
count, collect, save, reduce
* spark поддерживает:
** java
** scala
** python
Join на scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val sc = new SparkContext(master, appName, [sparkHome], [jars])
//transform
//или из текстового файла sc.textFile("file.txt")
val visits = sc.parallelize(
Seq(("index.html", "1.2.3.4"),
("about.html", "3.4.5.6"),
("index.html", "1.3.3.1")))
val pageNames = sc.parallelize(
Seq(("index.html", "Home"),
("about.html", "About")))
visits.join(pageNames)
//action
visits.saveAsTextFile("hdfs://file.txt")
// ("index.html", ("1.2.3.4", "Home"))
// ("index.html", ("1.3.3.1", "Home"))
// ("about.html", ("3.4.5.6", "About"))
word count
val file = sc.textFile("hdfs://...")
val sics = file.filter(_.contains("MAIL"))
val cached = sics.cache()
val ones = cached.map(_ => 1)
val count = ones.reduce(_+_)
val file = sc.textFile("hdfs://...")
val count = file.filter(_.contains(“MAIL")).count()
или
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
* Переменные для обмена данными между серверами
** broadcast variables - переменная только для чтения
val broadcastVar = sc.broadcast(Array(1, 2, 3)) ... broadcastVar.value** Accumulators - счетчики
val accum = sc.accumulator(0) accum += x accum.value
Yarn
планировщик ресурсов, которые избавляет от недостатков классического MR:* жесткое разделенеи ресурсов: можно освободить ресурсы от mapper после их полного выполнения и отдать все ресурсы reducer
* возможность разделять ресурсы не только между MR Задачами, но и другими процессами
* разделение происходит в понятии: озу, cpu, диск, сеть и т.д.
* он же производит запуск задач (не только MR) и восстанавливает в случае падения
* для работы нужны вспомогательные процессы:
** appserver - получение комманд от клиента
** resource server - север для выделяющий ресурсы
** node server - сервер для запуска задач и отслеживания за ними (на каждом сервере)
пятница, 17 февраля 2017 г.
Oracle: Hash агрегация и приблизительный DISTINCT
Список статей о внутреннем устройстве Oracle:
Нововведение Oracle 12.1 - приблизительный подсчет уникальных значений ( APPROX_COUNT_DISTINCT ~= count distinct ).
Классический подход к расчету числа уникальных значений предполагает создание хэш массива, где ключ = колонке таблицы, а в значении число совпадений.
Число элемнтов в хэш массиве будет равно числу уникальных данных в колонке таблицы:
Этот способ всем хорош, пока у нас достаточно памяти под хранение хэш массива.
При росте размера данных время и потребляемые ресурсы начинают катастрофически расти.
Пример со страницы antognini с разным числом уникальных значений на 10 млн. строк:
Скорость вычислений классическим способом падает вместе с ростом числа уникальных значений:
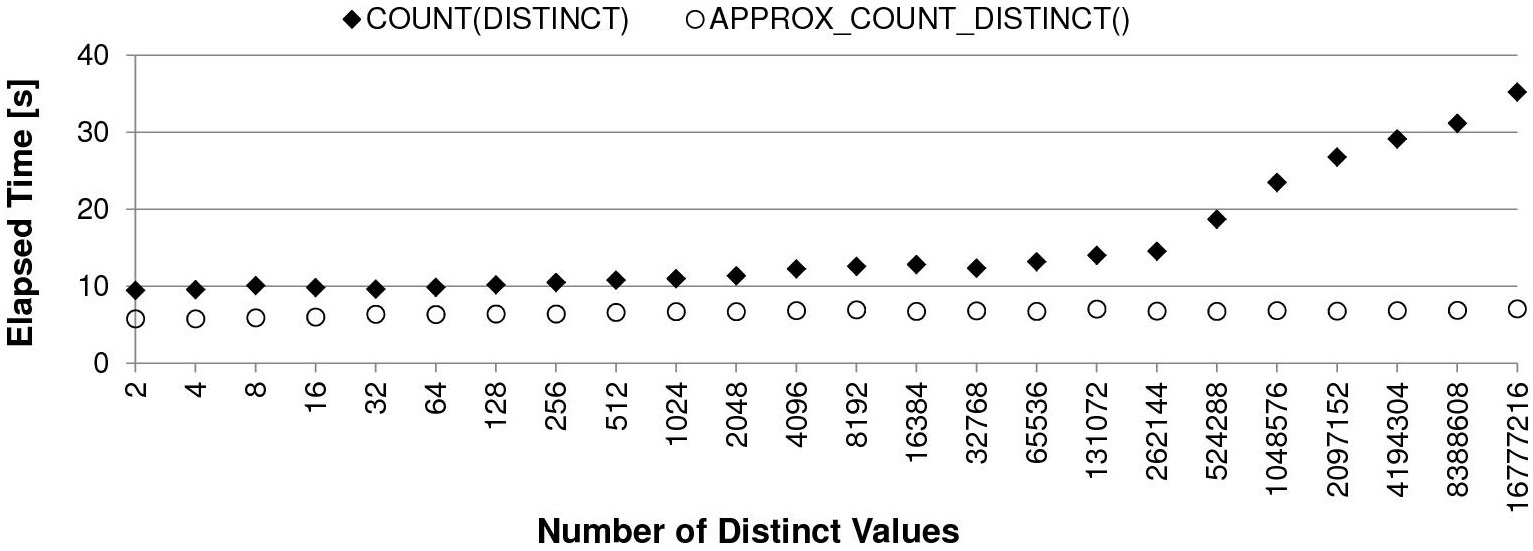
Пропорционально времени работы растет и потребление PGA памяти под хранение хэш массива:
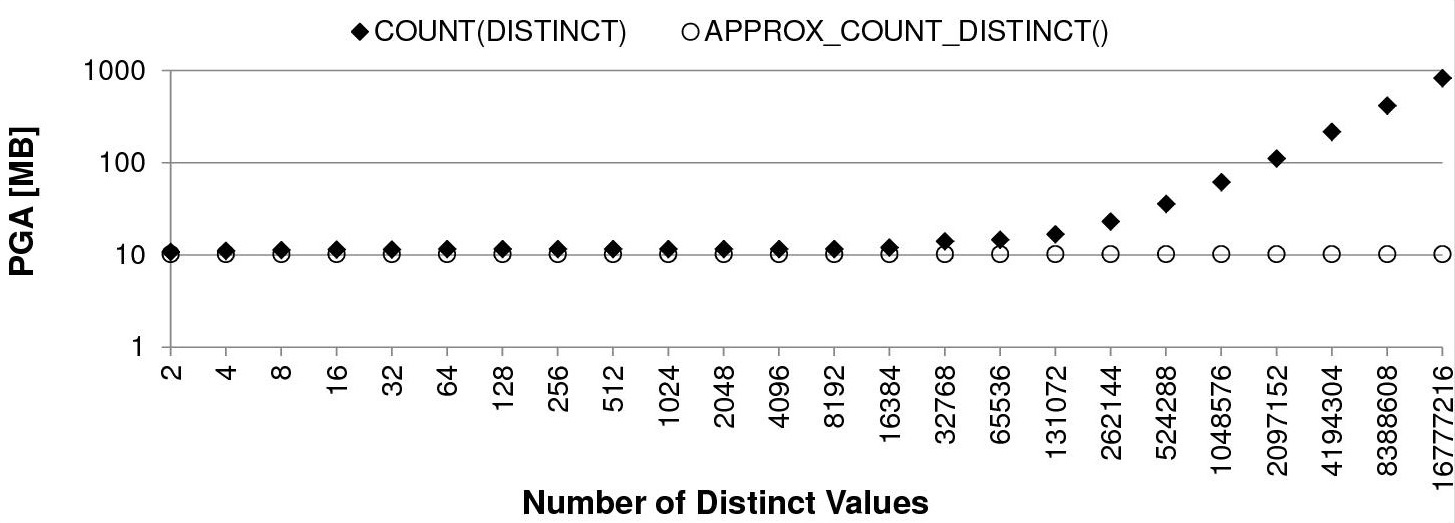
Чтобы решить проблему производительности/памяти и при этом получить приемлемый результат, можно применить приблизительный расчет числа уникальных значений.
Как и bloom filter он основан на вероятностных хэш значениях от данных.
Общий смысл приблизительного расчета (habr):
1. От каждого значения берется произвольная хэш функция
2. У каждого хэш значения определяется ранк первого ненулевого бита справа.
Вероятность того, что мы встретим хеш с рангом 1 равна 0.5, с рангом 2 — 0.25, с рангом r — 1 / 2ранг
Если запоминать наибольший обнаруженный ранг R, то 2R сгодится в качестве грубой оценки количества уникальных элементов среди уже просмотренных.
Такой подход даст нам приблизительное число уникальных значений, но с сильной ошибкой.
Для данного алгоритма есть усовершенствованный вариант HyperLogLog:
а. От битового представления хэш берется 8 первых левых бит. Они становятся ключом массива (2^8 = 256 значений)
б. Над массивов вычисляется формула:

где am - корректирующий коэффициент, m - размер массива = 256, M[] - массив ранков (hashes)
Для погрешности в 6.5% числитель этой формулы будет равен константе = 47072.7126712022335488.
Остается в цикле возвести 2 в -степень максимального ранка из каждого элемента массива:
Данный алгоритм уже дает приемлемый результат на больших данных, но серьезно ошибается на небольшом наборе.
Для небольших значение применяется дополнительная математическая корректировка:
Проведенных тест на 1-2 томах войны и мира показал результаты:
* реальное количество уникальных слов = 3737
* приблизительное число уникальных слов основываясь только на максимальном ранке первого ненулевого бита справа = 16384
* приблизительное число уникальных слов по формуле из п. б на массиве из 256 элементов = 3676
* приблизительное число уникальных слов по формуле и корректировке = 3676
При ошибке числа уникальных значений в 6,1% мы затратили константное число памяти под массив из 256 элементов, что в разы меньше, чем при обычном хэш массиве.
Полный исходный код на java можно посмотреть на github
- Order by сортировка
- BTree индекс
- Hash Join
- Bloom filter
- Lru cache
- Hash агрегация и приблизительный DISTINCT
Нововведение Oracle 12.1 - приблизительный подсчет уникальных значений ( APPROX_COUNT_DISTINCT ~= count distinct ).
Классический подход к расчету числа уникальных значений предполагает создание хэш массива, где ключ = колонке таблицы, а в значении число совпадений.
Число элемнтов в хэш массиве будет равно числу уникальных данных в колонке таблицы:
class RealDist {
HashMap words;
public RealDist() {
words = new HashMap();
}
public void set(String word) {
if (!words.containsKey(word)) {
words.put(word, 1);
} else {
words.put(word, words.get(word) + 1);
}
} //set
public int get() {
return words.size();
} //get
} // RealDist
Этот способ всем хорош, пока у нас достаточно памяти под хранение хэш массива.
При росте размера данных время и потребляемые ресурсы начинают катастрофически расти.
Пример со страницы antognini с разным числом уникальных значений на 10 млн. строк:
CREATE TABLE t
AS
WITH
t1000 AS (SELECT /*+ materialize */ rownum AS n
FROM dual
CONNECT BY level <= 1E3)
SELECT rownum AS id,
mod(rownum,2) AS n_2,
mod(rownum,4) AS n_4,
mod(rownum,8) AS n_8,
mod(rownum,16) AS n_16,
mod(rownum,32) AS n_32,
mod(rownum,64) AS n_64,
mod(rownum,128) AS n_128,
mod(rownum,256) AS n_256,
mod(rownum,512) AS n_512,
mod(rownum,1024) AS n_1024,
mod(rownum,2048) AS n_2048,
mod(rownum,4096) AS n_4096,
mod(rownum,8192) AS n_8192,
mod(rownum,16384) AS n_16384,
mod(rownum,32768) AS n_32768,
mod(rownum,65536) AS n_65536,
mod(rownum,131072) AS n_131072,
mod(rownum,262144) AS n_262144,
mod(rownum,524288) AS n_524288,
mod(rownum,1048576) AS n_1048576,
mod(rownum,2097152) AS n_2097152,
mod(rownum,4194304) AS n_4194304,
mod(rownum,8388608) AS n_8388608,
mod(rownum,16777216) AS n_16777216
FROM t1000, t1000, t1000
WHERE rownum <= 1E8;
Скорость вычислений классическим способом падает вместе с ростом числа уникальных значений:
Пропорционально времени работы растет и потребление PGA памяти под хранение хэш массива:
Чтобы решить проблему производительности/памяти и при этом получить приемлемый результат, можно применить приблизительный расчет числа уникальных значений.
Как и bloom filter он основан на вероятностных хэш значениях от данных.
Общий смысл приблизительного расчета (habr):
1. От каждого значения берется произвольная хэш функция
public static int fnv1a(String text) {
int hash = 0x811c9dc5;
for (int i = 0; i < text.length(); ++i) {
hash ^= (text.charAt(i) & 0xff);
hash *= 16777619;
}
return hash >>> 0;
} //fnv1a
2. У каждого хэш значения определяется ранк первого ненулевого бита справа.
// позиция первого ненулевого бита справа
public static int rank(int hash, int max_rank) {
int r = 1;
while ((hash & 1) == 0 && r <= max_rank) {
r++;
// смещаем вправо, пока не дойдет до hash & 1 == 1
hash >>>= 1;
}
return r;
} //rank
Вероятность того, что мы встретим хеш с рангом 1 равна 0.5, с рангом 2 — 0.25, с рангом r — 1 / 2ранг
Если запоминать наибольший обнаруженный ранг R, то 2R сгодится в качестве грубой оценки количества уникальных элементов среди уже просмотренных.
Такой подход даст нам приблизительное число уникальных значений, но с сильной ошибкой.
Для данного алгоритма есть усовершенствованный вариант HyperLogLog:
а. От битового представления хэш берется 8 первых левых бит. Они становятся ключом массива (2^8 = 256 значений)
public void set(String word) {
int hash = fnv1a(word);
// убираем 24 бита из 32 справа - остается 8 левых
// (=256 разных значений)
int k = hash >>> 24;
// если коллизия, то берем наибольший ранк
hashes[k] = Math.max(hashes[k], rank(hash, 24));
} // count
б. Над массивов вычисляется формула:
где am - корректирующий коэффициент, m - размер массива = 256, M[] - массив ранков (hashes)
Для погрешности в 6.5% числитель этой формулы будет равен константе = 47072.7126712022335488.
Остается в цикле возвести 2 в -степень максимального ранка из каждого элемента массива:
public double get_loglog() {
double count = 0;
for (int i = 0; i < hashes.length; i++) {
count += 1 / Math.pow(2, hashes[i]);
}
return 47072.7126712022335488 / count;
} //get_loglog
Данный алгоритм уже дает приемлемый результат на больших данных, но серьезно ошибается на небольшом наборе.
Для небольших значение применяется дополнительная математическая корректировка:
public int get() {
long pow_2_32 = 4294967296L;
double E = get_loglog();
// коррекция
if (E <= 640) {
int V = 0;
for (int i = 0; i < 256; i++) {
if (hashes[i] == 0) {
V++;
}
}
if (V > 0) {
E = 256 * Math.log((256 / (double) V));
}
} else if (E > 1 / 30 * pow_2_32) {
E = -pow_2_32 * Math.log(1 - E / pow_2_32);
}
// конец коррекции
return (int) Math.round(E);
} //get
Проведенных тест на 1-2 томах войны и мира показал результаты:
* реальное количество уникальных слов = 3737
* приблизительное число уникальных слов основываясь только на максимальном ранке первого ненулевого бита справа = 16384
* приблизительное число уникальных слов по формуле из п. б на массиве из 256 элементов = 3676
* приблизительное число уникальных слов по формуле и корректировке = 3676
При ошибке числа уникальных значений в 6,1% мы затратили константное число памяти под массив из 256 элементов, что в разы меньше, чем при обычном хэш массиве.
Полный исходный код на java можно посмотреть на github
среда, 14 декабря 2016 г.
Oracle: вероятностный Bloom filter
Список статей о внутреннем устройстве Oracle:
Более редкая разновидность хэширования данных и вероятностной фильтрации данных - bloom filter
Раньше я уже описывал bloom filter в параллельных запросах со стороны разработчика бд: Oracle: оптимизация параллельных запросов, сегодня копнем немного глубже, с кодом bloom filter на java.
Bloom filter — это вероятностная структура данных, позволяющая компактно хранить множество элементов и проверять принадлежность заданного элемента к множеству. При этом существует возможность получить ложноположительное срабатывание (элемента в множестве нет, но структура данных сообщает, что он есть), но не ложноотрицательное.
Фильтр Блума может использовать любой объём памяти, заранее заданный пользователем, причём чем он больше, тем меньше вероятность ложного срабатывания.

Пример фильтра Блума с 18 бит в карте и 3 функциям хэширования, хранящего множество {x, y, z}. Цветные стрелки указывают на места в битовом массиве, соответствующие каждому элементу множества. Этот фильтр Блума определит, что элемент w не входит в множество, так как один из соответствующих ему битов равен нулю.
Основное предназначение - предфильтрация данных в источнике до передачи их в базу данных.
Принцип применения блум фильтра при join:
1. Левая таблица читается с диска и фильтруется (plan line = 3)
2. На основе левой таблицы создается битовая карта блум фильтра (:BF0000 plan line = 2)
3. Блум фильтр передается в источник правой таблицы (:BF0000 plan line = 4)
4. Строки правой таблицы фильтруются через блум фильтр (:BF0000 plan line = 5 - storage(SYS_OP_BLOOM_FILTER(:BF0000,"R"."L_ID")))
5. В бд передается уже частично отфильтрованная правая таблица
6. Выполняется join (plan line = 1)
Детальное описание с кодом на java:
1. Блум фильтр состоит из массива бит произвольной длинны. В моем случае под битовый массив выделена переменная long в 64 бита:
2. Определяется hash_num функций хэширования. На входе функции произвольная строка, на выходе номер бита в битовой карте для установки в 1.
3. Устанавливаем биты в битовой карте для hash_nums хэш функций
4. Обратная операция - тестирование строки на вероятное наличие элемента в блум фильтре: хэшируем и проверяем бит в блум фильтре
Очевидно, чем больше битовая карта в блум фильтре, тем точней результат - меньше ложных срабатываний.
Зависимость определяется формулой:
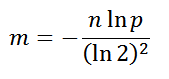
, где n — предполагаемое количество элементов хранящихся в фильтре-множестве, p — вероятность ложного срабатывания, m - число бит в карте
Вероятность ложного срабатывания от числа бит в карте и кол-ва элементов:

Также использование нескольких функции хэширования дает преимущество при достаточном размере блум фильтра:
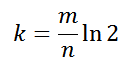
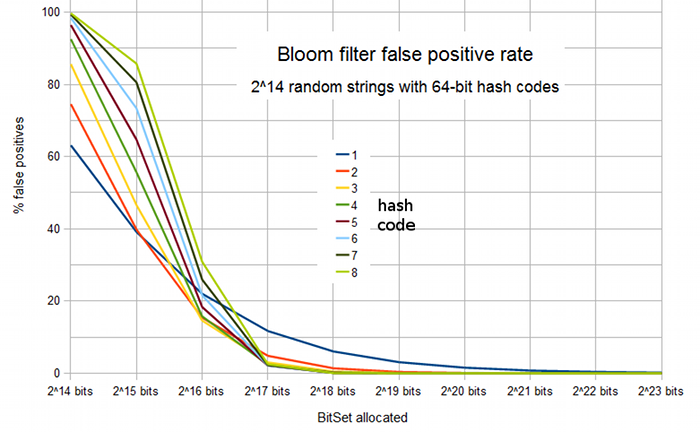
График вероятности ложного срабатывания от размера массива и числа функций хэширования:
Практическое применение Bloom фильтра в Oracle:
* Partition pruning - усечение просматриваемых партиций
На основе фильтра левой таблицы выбираются секции для сканирования из правой, что позволит не сканировать таблицу целиком.
* RAC - уменьшение сетевого трафика между кластерными нодами
Для уменьшения сетевого взаимодействия между кластерными нодами, если левую таблицу читает 1 нода, а правую нода 2.
Применение блум фильтра уменьшает размер пересылаемых данных правой таблицы из ноды 2 в ноду 1 до выполнения соединения.
* Exadata или Map reduce движок в качестве источника данных
Массовая параллельная обработка внутри exadata проходит быстрей, чем аналогичная операция внутри бд Oracle.
Из-за этого при наличии exadata Oracle стремится произвести максимальное число фильтрации в источнике до передачи в базу.
* In Memory хранилище данных
Аналогично exadata, inmemory движок может производить фильтрацию внутри себя и это будет быстрей, чем выполнять join на полном наборе данных.
При наличии таких данных Oracle стремится произвести максимум фильтрации до передачи данных в бд.
* Parallel - параллельные запросы
Взаимодействие параллеьлных поток происходит через координатор и если 1 поток читает левую таблицу, а 2 поток - правую, то выгодней и быстрей отфильтровать правую таблицу блум фильтром и передать в первый поток уже отфильтрованные данные.
* Гетерогенные запросы через дблинк (возможно)
Сетевое взаимодействие очень дорогое по сравнению с работой с памятью и даже диском. Из-за этого было бы выгодно отфильтровать правую таблицу на удаленной бд до ее передачи в нашу.
Полную реализацию блум фильтра можно видеть здесь: https://github.com/pihel/java/blob/master/Hash/BloomFilter.java
- Order by сортировка
- BTree индекс
- Hash Join
- Bloom filter
- Lru cache
- Hash агрегация и приблизительный DISTINCT
Более редкая разновидность хэширования данных и вероятностной фильтрации данных - bloom filter
Раньше я уже описывал bloom filter в параллельных запросах со стороны разработчика бд: Oracle: оптимизация параллельных запросов, сегодня копнем немного глубже, с кодом bloom filter на java.
Bloom filter — это вероятностная структура данных, позволяющая компактно хранить множество элементов и проверять принадлежность заданного элемента к множеству. При этом существует возможность получить ложноположительное срабатывание (элемента в множестве нет, но структура данных сообщает, что он есть), но не ложноотрицательное.
Фильтр Блума может использовать любой объём памяти, заранее заданный пользователем, причём чем он больше, тем меньше вероятность ложного срабатывания.
Пример фильтра Блума с 18 бит в карте и 3 функциям хэширования, хранящего множество {x, y, z}. Цветные стрелки указывают на места в битовом массиве, соответствующие каждому элементу множества. Этот фильтр Блума определит, что элемент w не входит в множество, так как один из соответствующих ему битов равен нулю.
Основное предназначение - предфильтрация данных в источнике до передачи их в базу данных.
Принцип применения блум фильтра при join:
1. Левая таблица читается с диска и фильтруется (plan line = 3)
2. На основе левой таблицы создается битовая карта блум фильтра (:BF0000 plan line = 2)
3. Блум фильтр передается в источник правой таблицы (:BF0000 plan line = 4)
4. Строки правой таблицы фильтруются через блум фильтр (:BF0000 plan line = 5 - storage(SYS_OP_BLOOM_FILTER(:BF0000,"R"."L_ID")))
5. В бд передается уже частично отфильтрованная правая таблица
6. Выполняется join (plan line = 1)
create table l as select level as id, 'name_' || level as title, rpad('*', level) as pad from dual connect by level <= 50;
create table r as select rownum as id, mod(rownum, 50) as l_id, rpad('*', 20) as pad
from (select * from dual connect by level <= 1000 ) join (select * from dual connect by level <= 1000 ) on 1=1;
begin
DBMS_STATS.GATHER_TABLE_STATS(USER, 'L');
DBMS_STATS.GATHER_TABLE_STATS(USER, 'R');
end;
explain plan for
select *
from l
join r on l.id = r.l_id
WHERE l.title = 'name_5';
select * from table(dbms_xplan.display(format=>'ALLSTATS ALL ADVANCED'));
Plan hash value: 3967001914
----------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20000 | 1308K| 184 (20)| 00:00:01 |
|* 1 | HASH JOIN | | 20000 | 1308K| 184 (20)| 00:00:01 |
| 2 | JOIN FILTER CREATE | :BF0000 | 1 | 38 | 2 (0)| 00:00:01 |
|* 3 | TABLE ACCESS STORAGE FULL| L | 1 | 38 | 2 (0)| 00:00:01 |
| 4 | JOIN FILTER USE | :BF0000 | 1000K| 27M| 171 (15)| 00:00:01 |
|* 5 | TABLE ACCESS STORAGE FULL| R | 1000K| 27M| 171 (15)| 00:00:01 |
----------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$58A6D7F6
3 - SEL$58A6D7F6 / L@SEL$1
5 - SEL$58A6D7F6 / R@SEL$1
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("L"."ID"="R"."L_ID")
3 - storage("L"."TITLE"='name_5')
filter("L"."TITLE"='name_5')
5 - storage(SYS_OP_BLOOM_FILTER(:BF0000,"R"."L_ID"))
filter(SYS_OP_BLOOM_FILTER(:BF0000,"R"."L_ID"))
Детальное описание с кодом на java:
1. Блум фильтр состоит из массива бит произвольной длинны. В моем случае под битовый массив выделена переменная long в 64 бита:
package Hash;
import java.util.concurrent.ThreadLocalRandom;
public class BloomFilter {
//long переменная в 64бита под битовый массив
private long data;
//битов в битовой карте = числу битов в long
private int bit_array_size = Long.SIZE;
2. Определяется hash_num функций хэширования. На входе функции произвольная строка, на выходе номер бита в битовой карте для установки в 1.
//примесь для случайного хэширования
private int seed = ThreadLocalRandom.current().nextInt(1, bit_array_size);
//хэшировани = номер бита в битовом массиве
public long hashCode(String s, int hash_num) {
long result = 1;
//для каждого байта в строке
for (int i = 0; i < s.length(); ++i) {
//применяем хэш функцию под номером hash_num и обрезаем по маске
//простая хэш функция = ascii значение буквы * примесь * номер функции * хэш от предыдущей функции & обрезка по маске
//1 = (1 * 1 + 58)
//1 = ( 0001 * 0001 + 11 0001 ) & 1111 1111 1111 1111
result = ((hash_num + seed) * result + s.charAt(i)) & this.hashMask;
}
3. Устанавливаем биты в битовой карте для hash_nums хэш функций
//установить index бит в битовой карте
public void setBit(long index) {
//= битовая карта OR 1 смещенное влево на index
this.data = this.data | (1L << index );
} //setbit
//добавить элемент в блум фильтр
public void add(String s) {
//++ счетчик элементов
cnt++;
//для каждой хэш функции
for(int i = 1; i <= hash_nums; i++) {
//расчитаем номер индекса в битовой карте и установим его
long index = hashCode(s, i);
setBit(index);
}
} //add
4. Обратная операция - тестирование строки на вероятное наличие элемента в блум фильтре: хэшируем и проверяем бит в блум фильтре
//получить значение бита на index месте
public long getBit(long index) {
//=битовая карта смещенная вправо на index мест (>>> пустые места справа заполняются 0)
// & 01 - проверка только крайнего правого бита (все остальные игнорируются)
return ( this.data >>> index ) & 1;
} //getBit
//проверка наличия элемента в блум фильтре
public boolean test(String s) {
//для каждой хэш функции
for(int i = 1; i <= hash_nums; i++) {
//определяем номер бита в битовой карте
long index = hashCode(s, i);
//если хотябы одна проверка не прошла - элемента нет
if( getBit(index) == 0L ) return false;
}
//иначе элемент вероятно есть
return true;
} //test
Очевидно, чем больше битовая карта в блум фильтре, тем точней результат - меньше ложных срабатываний.
Зависимость определяется формулой:
, где n — предполагаемое количество элементов хранящихся в фильтре-множестве, p — вероятность ложного срабатывания, m - число бит в карте
//вероятность ложного срабатывания
public double getFalsePossb() {
if(cnt == 0) return 0;
return 1 / Math.pow(Math.E, bit_array_size * Math.log(2) * Math.log(2) / cnt );
} //getFalsePossb
Вероятность ложного срабатывания от числа бит в карте и кол-ва элементов:
Также использование нескольких функции хэширования дает преимущество при достаточном размере блум фильтра:
//оптимальное число функций хэширования
public int getOptimalFncCnt() {
if(cnt == 0) return 1;
return (int)Math.ceil( bit_array_size / cnt * Math.log(2) );
} //getOptimalFncCnt
График вероятности ложного срабатывания от размера массива и числа функций хэширования:
Практическое применение Bloom фильтра в Oracle:
* Partition pruning - усечение просматриваемых партиций
На основе фильтра левой таблицы выбираются секции для сканирования из правой, что позволит не сканировать таблицу целиком.
* RAC - уменьшение сетевого трафика между кластерными нодами
Для уменьшения сетевого взаимодействия между кластерными нодами, если левую таблицу читает 1 нода, а правую нода 2.
Применение блум фильтра уменьшает размер пересылаемых данных правой таблицы из ноды 2 в ноду 1 до выполнения соединения.
* Exadata или Map reduce движок в качестве источника данных
Массовая параллельная обработка внутри exadata проходит быстрей, чем аналогичная операция внутри бд Oracle.
Из-за этого при наличии exadata Oracle стремится произвести максимальное число фильтрации в источнике до передачи в базу.
* In Memory хранилище данных
Аналогично exadata, inmemory движок может производить фильтрацию внутри себя и это будет быстрей, чем выполнять join на полном наборе данных.
При наличии таких данных Oracle стремится произвести максимум фильтрации до передачи данных в бд.
* Parallel - параллельные запросы
Взаимодействие параллеьлных поток происходит через координатор и если 1 поток читает левую таблицу, а 2 поток - правую, то выгодней и быстрей отфильтровать правую таблицу блум фильтром и передать в первый поток уже отфильтрованные данные.
* Гетерогенные запросы через дблинк (возможно)
Сетевое взаимодействие очень дорогое по сравнению с работой с памятью и даже диском. Из-за этого было бы выгодно отфильтровать правую таблицу на удаленной бд до ее передачи в нашу.
Полную реализацию блум фильтра можно видеть здесь: https://github.com/pihel/java/blob/master/Hash/BloomFilter.java
суббота, 3 декабря 2016 г.
Oracle: реализация hash соединения
Список статей о внутреннем устройстве Oracle:
Следующий аспект бд - хэширование данных
Раньше я уже описывал hash join со стороны разработчика бд: Основы стоимостной оптимизации join, сегодня копнем немного глубже, с кодом hash join на java.
Хэширование - преобразование массива входных данных произвольной длины в выходную битовую строку фиксированной длины, выполняемое определённым алгоритмом.
Преимуществом массива фиксированной длины является константное время доступа к его элементам из-за размещения ограниченного набора в процессорном кэше.
Самая большая проблема - это выбор хэширующей функции, которая давала бы минимум коллизий (одинаковых значений хэш функции для разных ключей массива).
Идеальная хэширующая функция не должна давать коллизий, но в реальности такую функцию сложно получить.
В моем случае алгоритмом хэширование я выбрал остаток от деления. Число в знаменателе даст нам такое же число элементов в хэш массиве.
Для разрешения проблемы коллизий используется 2 подхода, оба из них в зависимости от числа коллизий для доступа к нужному элементу дают от 1 до N обращений:
1. Открытая адресация
 Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место.
Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место.
Пример:
Массив из элементов: 1, 11, 2, 3
Хэширующая функция: остаток от деления на 10
Результирующий хэш массив:
Реализацию на java можно посмотреть здесь.
2. Метод цепочек
 Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции.
Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции.
Пример на том же массиве и той же хэширующей функции:
3. Метод красно-черного дерева
В случае большого числа коллизий, когда все элементы попадают в одну хэш секцию, для хранения данных секции целесообразно использовать красно-черное дерево, замен списка во 2 методе. В этом случае поиск элемента будет осуществляться за логарифмическое время, вместо линейного в списке.
Плюсы и минусы подходов:
Детали реализации Oracle:
Хэширование цепочками наиболее понятное, но оно же дает худшую производительность, т.к. не использует кэш процессора из-за постоянных переходов по ссылке.
По этому все нагруженные реализации используют Hash таблицы с открытой адресацией, где все данные лежат рядом и используют кэш сопроцессора.
 Слева графически представлен механизм поиска в хэш таблице Oracle.
Слева графически представлен механизм поиска в хэш таблице Oracle.
Изменения в реализации хэш таблиц Oracle:
* Хэш таблица над таблицей бд может быть сколь угодно большой и она может не поместиться в памяти
* битовая карта над данными в хэш таблице, если соответствующий бит таблицы установлен, то элемент есть в хэш таблице, иначе строку можно даже не искать.
Когда Oracle выбирает соединение хэшированием:
В основе выбора способ лежит стоимостная оценка:
Стоимость соединения вложенными циклами (NL) = стоимость получения T1 + кардинальность Т1 * Стоимость одного обращения к Т2
Стоимость соединения хэшированием (hash) = стоимость получения Т1 + стоимость получения Т2 + стоимость хэширования и сравнения.
Исходя из этих формул можно сделать вывод, что hash соединение выгодней, когда :
* Нужно считать большой объем данных для соединения или на правой таблице таблице нет индекса.
Многоблочное считывание при hash join выгодней, чем последовательное одноблочное сканирование индекса правой таблицы.
* Параллельное выполнение запросов - хэширование и поиск в хэш таблице хорошо распараллеливается, поиск по связанному списку индекса практически не параллелится.
Когда hash join не может быть использован:
* Поиск по диапазону (или любой операции отличной от = ) не применим для хэш таблицы, результат функции дает непоследовательные данные, которые не просканировать последовательно.
Рассмотрим подробней вариант, однопроходного поиска в хэш таблице, т.е. когда объема памяти достаточно, чтобы целиком разместить хэш секцию.
Для простоты будет использоваться Hash таблица цепочками.
- Order by сортировка
- BTree индекс
- Hash Join
- Bloom filter
- Lru cache
- Hash агрегация и приблизительный DISTINCT
Следующий аспект бд - хэширование данных
Раньше я уже описывал hash join со стороны разработчика бд: Основы стоимостной оптимизации join, сегодня копнем немного глубже, с кодом hash join на java.
Хэширование - преобразование массива входных данных произвольной длины в выходную битовую строку фиксированной длины, выполняемое определённым алгоритмом.
Преимуществом массива фиксированной длины является константное время доступа к его элементам из-за размещения ограниченного набора в процессорном кэше.
Самая большая проблема - это выбор хэширующей функции, которая давала бы минимум коллизий (одинаковых значений хэш функции для разных ключей массива).
Идеальная хэширующая функция не должна давать коллизий, но в реальности такую функцию сложно получить.
В моем случае алгоритмом хэширование я выбрал остаток от деления. Число в знаменателе даст нам такое же число элементов в хэш массиве.
Для разрешения проблемы коллизий используется 2 подхода, оба из них в зависимости от числа коллизий для доступа к нужному элементу дают от 1 до N обращений:
1. Открытая адресация
Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место.Пример:
Массив из элементов: 1, 11, 2, 3
Хэширующая функция: остаток от деления на 10
Результирующий хэш массив:
[1] = 1 (остаток от деления 1 на 10 = 1, т.к. ключ 1 был пустой, то он и занимается) [2] = 11 (остаток от деления 11 на 10 = 1, это коллизия для предыдущего элемента. Т.к. ключ 1 занят, то берется следующий пустой справа = 2) [3] = 2 (остаток от деления = 2, т.к. элемент занят, то берется следующий = 3) [4] = 3 (и т.д.)
Реализацию на java можно посмотреть здесь.
2. Метод цепочек
Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции.Пример на том же массиве и той же хэширующей функции:
[1] = 1 -> 11 [2] = 2 [3] = 3 [4] = 4
3. Метод красно-черного дерева
В случае большого числа коллизий, когда все элементы попадают в одну хэш секцию, для хранения данных секции целесообразно использовать красно-черное дерево, замен списка во 2 методе. В этом случае поиск элемента будет осуществляться за логарифмическое время, вместо линейного в списке.
Плюсы и минусы подходов:
| Сравниваемое свойство | Цепочки | Открытая адресация |
| Разрешение коллизий | Используются дополнительные списки | Хранится в самом хэш массиве |
| Использование памяти | Дополнительная память для указателей в списке. В случае неудачной хэш функции, если все элементы легли в один элемент массива (хэш секцию), то размер памяти будет почти в 2 раза больше, т.к. необходимая память под указатели будет равна памяти под ключи. |
Нет доп. расходов |
| Зависимость производительности от заполненности таблицы | Прямо пропорционально значению = число элементов / кол-во хэш секции таблицы | число элементов / ( кол-во хэш секции таблицы - число элементов ) |
| Возможность записи числа элементов больше размера хэш таблицы | Да, за счет записи коллизий в список | Нет, т.к. колллизии храняться в томже массиве |
| Простота удаления | Да, удаляется элемент из списка | Нет, пустое место нужно помечать удаленным, а не очищать физически. Т.к. при вставке ищутся пусты места справа, что может сломать последовательность |
| Использование кэша процессора | Нет (переходы по ссылке) | Да (Все данные рядом) |
Детали реализации Oracle:
Хэширование цепочками наиболее понятное, но оно же дает худшую производительность, т.к. не использует кэш процессора из-за постоянных переходов по ссылке.
По этому все нагруженные реализации используют Hash таблицы с открытой адресацией, где все данные лежат рядом и используют кэш сопроцессора.
Слева графически представлен механизм поиска в хэш таблице Oracle.Изменения в реализации хэш таблиц Oracle:
* Хэш таблица над таблицей бд может быть сколь угодно большой и она может не поместиться в памяти
* битовая карта над данными в хэш таблице, если соответствующий бит таблицы установлен, то элемент есть в хэш таблице, иначе строку можно даже не искать.
Когда Oracle выбирает соединение хэшированием:
В основе выбора способ лежит стоимостная оценка:
Стоимость соединения вложенными циклами (NL) = стоимость получения T1 + кардинальность Т1 * Стоимость одного обращения к Т2
Стоимость соединения хэшированием (hash) = стоимость получения Т1 + стоимость получения Т2 + стоимость хэширования и сравнения.
Исходя из этих формул можно сделать вывод, что hash соединение выгодней, когда :
* Нужно считать большой объем данных для соединения или на правой таблице таблице нет индекса.
Многоблочное считывание при hash join выгодней, чем последовательное одноблочное сканирование индекса правой таблицы.
* Параллельное выполнение запросов - хэширование и поиск в хэш таблице хорошо распараллеливается, поиск по связанному списку индекса практически не параллелится.
Когда hash join не может быть использован:
* Поиск по диапазону (или любой операции отличной от = ) не применим для хэш таблицы, результат функции дает непоследовательные данные, которые не просканировать последовательно.
Рассмотрим подробней вариант, однопроходного поиска в хэш таблице, т.е. когда объема памяти достаточно, чтобы целиком разместить хэш секцию.
Для простоты будет использоваться Hash таблица цепочками.
вторник, 15 ноября 2016 г.
Oracle: реализация btree индекса
Список статей о внутреннем устройстве Oracle:
Следующий важный аспект бд - индексирование данных в таблицах.
Раньше я уже описывал индексирование со стороны разработчика бд: http://blog.skahin.ru/2015/04/oracle.html, сегодня копнем немного глубже, с кодом btree индекса на java.
B+Tree - Дерево поиска. С точки зрения внешнего логического представления, сбалансированное, сильно ветвистое дерево во внешней памяти.
Дерево ( BPTree ) состоит из корня ( root ), внутренних узлов ( INode ) и листьев ( LNode ), корень может быть либо листом, либо узлом с двумя и более потомками.
Сбалансированность означает, что длина любых двух путей от корня до листьев совпадает.
Ветвистость дерева — это свойство каждого узла дерева ссылаться на большое число узлов-потомков ( Node[] children ).
С точки зрения физической организации B-дерево представляется как мультисписочная структура страниц внешней памяти, то есть каждому узлу дерева соответствует блок внешней памяти (блок / страница). Внутренние и листовые страницы обычно имеют разную структуру.
При этом данные хранятся только в последовательно связанных листьях ( LNode.next ), а в ветвях только ссылки на листья дерева ( INode.children ).

B-дерево может применяться для структурирования (индексирования) информации на жёстком диске. Время доступа к произвольному блоку на жёстком диске очень велико (порядка миллисекунд), поскольку оно определяется скоростью вращения диска и перемещения головок. Поэтому важно уменьшить количество узлов, просматриваемых при каждой операции. Использование поиска по списку каждый раз для нахождения случайного блока могло бы привести к чрезмерному количеству обращений к диску, вследствие необходимости осуществления последовательного прохода по всем его элементам, предшествующим заданному; тогда как поиск в B-дереве, благодаря свойствам сбалансированности и высокой ветвистости, позволяет значительно сократить количество таких операций.
Перейдем к особенностям реализации Oracle:
1. Т.к. бд хранит и считывает данные в блоках/страницах, то размер листа/ветви = размеру блока. ( rows_block )
2. Вставка
При достижении максимального числа элементов в блоке ( rows_block ) , лист должен разбиться на 2 части ( BPTree.Insert, LNode.Insert , INode.Insert ), а копия среднего элемента перейти на ветвь выше ( Split ) рекурсивно (максимальное число ветвлений = 24. В Oracle этот параметр называется blevel (BPTree.getBLevel) = height - 1 )
В Oracle реализован особенный алгоритм: если вставка элемента идет в крайний правый блок индекса (Node.last), то разделение идет в соотношении 90/10.
Это значительно снижает размер индекса при вставке последовательных данных, т.к. данные в блоках получаются плотно упакованы.
Такая ситуация часто бывает на первичном ключе, генерируемый последовательностью.
Если вставка идет в середину индекса, то алгоритм стандартный - блок сплитится в соотношении 50/50, что приводит к появлению пустых мест и физическому разрастанию индекса на диске.
Пример индекса с числом элементов в блоке = 3:
* Вставка последовательных данных: {1, 2, 3, 4, 5, 6, 7, 8, 9}
переполняющий элемент сразу идет в правый новый блок, не разделяя левый на 2 части:
Всего 3 листовых блока и высота дерева = 2
* Вставка данных в обратном порядке:
Массив из 3 элементов постоянно разбивается на 2 части:
Хороший визуализатор b+tree дерева можно видеть тут
Тут ситуация хуже, индекс сильно разряжен: 7 листовых блоков и высота дерева = 3.
Индекс будет почти в 2 раза больше весить на диске и для обращений к нему нужно будет делать 3 чтения с диска, вместо 2 при последовательной.
Стоит заметить, что последовательная вставка в индекс это не всегда хорошо.
Если вставка преобладает перед чтением, то insert в разные части индекса лучше, чем последовательная в один блок. Т.к. это обеспечивает большую конкуренцию за общий ресурс и в итоге приведет к buffer busy wait. Специально для перемешивания данных используются реверсивные индексы (http://blog.skahin.ru/2015/04/oracle.html).
3. Поиск элемента
* начинаем с корня дерева (считываем его с диска) ( BPTree.indexScan )
* в блоке ветви бинарным поиском ищем элемент = искомому или первый больше его, если искомого нет в ветви (INode.getLoc)
* если нашли, то спускаемся налево, иначе если искомый элемент больше максимального в блоке ветви, то двигаемся направо (считывание с диска) (inner.children[idx])
* рекурсивно повторяем N раз = высота дерева - 1, пока не дойдем до листа (считывание с диска) (LNode leaf)
* в упорядоченном массиве блока листа бинарным поиском (считывание с диска) (leaf.getLoc)
Итого элемент будет найден за число считываний с диска = высоте дерева. Затраты CPU = высота дерева * log2(число строк в блоке)
3. При удалении данных из индекса, в целях ускорения, элемент физически не удаляется, а лишь помечается удаленным. Тем самым индекс не становится меньше весом.
Для устранения эффектов из п. 2 и 3 индекс необходимо периодически ребилдить rebuild
4. Операции min/max поиска также осуществляются за константное время = высоте дерева (операция index min/max scan) ( BPtree.getMin / BPtree.getMax )
5. Т.к. данные упорядоченные, то поиск нужного элемента внутри блока происходит с помощью бинарного поиска (LNode.getLoc).
Так что если сравнивать время доступа к таблице в 1 блок и к индексу в 1 блок: оба варианта дают 1 физическое чтение с диска, но поиск по индексу будет быстрей, т.к. для поиска элемента в упорядоченном массиве индекса log2(N) операций, а в неупорядоченной таблице - это всегда линейный поиск со стоимостью = N
6. Упорядоченность данных также позволяет искать данные по диапазону (BPTree.rangeScan):
* Находим стартовый элемент (Node.getLoc)
* Двигаемся по блоку вправо (while(leaf != null))
* Если дошли до конца блока, то переходим по ссылке на следующий ( leaf = leaf.next )
* доходим до элемента большего правой границы диапазона ( leaf.keys[i].compareTo(to_key) > 0 )
Это операция последовательного чтения массива, к сожалению, она никак не может быть распараллелена.
Также если в индексе после столбца, по которому идет сканирование по диапазаону, есть еще столбец, то он не сможет быть использован для доступа к нужному блоку индекса для старта, только для дофильтрации диапазона. Такой метод не уменьшит число физических чтений блоков индекса с диска.
7. null Значения
Oracle в отличии от других бд не хранит в индексе полностью пустые значения. Это значит что при поиске "idx_cold is null" не будет использоваться.
Это ограничение можно обойти, если создать индекс из 2 полей: нужного и любого другого. В качестве второго поля можно исопльзовать даже константу.
К примеру:
В этом случае все значения колонки col, включая null, будут храниться в индексе и будет работать "col is null" сканирование.
8. index scip scan
9. Сжатые индексы
Не релизовывалось в данном классе.
Описание см. http://blog.skahin.ru/2015/04/oracle.html
10. Структура блока из 2 столбцов.
Т.е. фактической разницы между индексом из 1 или 2 и более столбцов особо разницы нет.
12. Фактор кластеризации - соответствие последовательности элементов в индексе элементам в таблице. (BPtree.getClusterFactor)

Наилучший вариант, когда данные в таблице отсортированы на техже столбцах, что в индексе ( не важно прмямую или обратную). Тогда фактор кластеризации будет равен числу блоков в таблице.
Если же наоборот, то для чтения каждого элемента в индексе нужно считывать новый блок таблицы с диска, тогда фактор кластеризации = числу строк таблицы.
13. Index full scan - полное сканирование индекса (BPtree.fullScan)
14. Index Desc Scan - сканирование в обратном порядке
Индекс строится в прямом порядке и имеет ссылку в листовом блоке только на следующий.
То в случае запроса:
Индекс также фильтруется как в п. 6, но обращения к таблице по rowid идет в обратном порядке, т.е. данные повторно не сортируются (order by idx_col desc), т.к. строки уже возвращаются из индекса в обратном порядке.
Исходный код B+дерева на java:
Полный код класса и юнит тесты можно посмотреть здесь: https://github.com/pihel/java/blob/master/BPTree/
- Oracle: реализация order by сортировки
- Oracle: реализация btree индекса
- Hash Join
- Bloom filter
- Lru cache
- Hash агрегация и приблизительный DISTINCT
Следующий важный аспект бд - индексирование данных в таблицах.
Раньше я уже описывал индексирование со стороны разработчика бд: http://blog.skahin.ru/2015/04/oracle.html, сегодня копнем немного глубже, с кодом btree индекса на java.
B+Tree - Дерево поиска. С точки зрения внешнего логического представления, сбалансированное, сильно ветвистое дерево во внешней памяти.
Дерево ( BPTree ) состоит из корня ( root ), внутренних узлов ( INode ) и листьев ( LNode ), корень может быть либо листом, либо узлом с двумя и более потомками.
Сбалансированность означает, что длина любых двух путей от корня до листьев совпадает.
Ветвистость дерева — это свойство каждого узла дерева ссылаться на большое число узлов-потомков ( Node[] children ).
С точки зрения физической организации B-дерево представляется как мультисписочная структура страниц внешней памяти, то есть каждому узлу дерева соответствует блок внешней памяти (блок / страница). Внутренние и листовые страницы обычно имеют разную структуру.
При этом данные хранятся только в последовательно связанных листьях ( LNode.next ), а в ветвях только ссылки на листья дерева ( INode.children ).
B-дерево может применяться для структурирования (индексирования) информации на жёстком диске. Время доступа к произвольному блоку на жёстком диске очень велико (порядка миллисекунд), поскольку оно определяется скоростью вращения диска и перемещения головок. Поэтому важно уменьшить количество узлов, просматриваемых при каждой операции. Использование поиска по списку каждый раз для нахождения случайного блока могло бы привести к чрезмерному количеству обращений к диску, вследствие необходимости осуществления последовательного прохода по всем его элементам, предшествующим заданному; тогда как поиск в B-дереве, благодаря свойствам сбалансированности и высокой ветвистости, позволяет значительно сократить количество таких операций.
Перейдем к особенностям реализации Oracle:
1. Т.к. бд хранит и считывает данные в блоках/страницах, то размер листа/ветви = размеру блока. ( rows_block )
2. Вставка
При достижении максимального числа элементов в блоке ( rows_block ) , лист должен разбиться на 2 части ( BPTree.Insert, LNode.Insert , INode.Insert ), а копия среднего элемента перейти на ветвь выше ( Split ) рекурсивно (максимальное число ветвлений = 24. В Oracle этот параметр называется blevel (BPTree.getBLevel) = height - 1 )
В Oracle реализован особенный алгоритм: если вставка элемента идет в крайний правый блок индекса (Node.last), то разделение идет в соотношении 90/10.
Это значительно снижает размер индекса при вставке последовательных данных, т.к. данные в блоках получаются плотно упакованы.
Такая ситуация часто бывает на первичном ключе, генерируемый последовательностью.
Если вставка идет в середину индекса, то алгоритм стандартный - блок сплитится в соотношении 50/50, что приводит к появлению пустых мест и физическому разрастанию индекса на диске.
Пример индекса с числом элементов в блоке = 3:
* Вставка последовательных данных: {1, 2, 3, 4, 5, 6, 7, 8, 9}
переполняющий элемент сразу идет в правый новый блок, не разделяя левый на 2 части:
1 2 3 . > 4 4 5 6 . > 7 7 8 9( > - ветвь, . - высота ветви -- вывод функции dump )
Всего 3 листовых блока и высота дерева = 2
* Вставка данных в обратном порядке:
Массив из 3 элементов постоянно разбивается на 2 части:
1 2 3 . > 4 4 . > 5 5 . . > 6 6 . > 7 7 . . > 8 8 . > 9 9
Хороший визуализатор b+tree дерева можно видеть тут
Тут ситуация хуже, индекс сильно разряжен: 7 листовых блоков и высота дерева = 3.
Индекс будет почти в 2 раза больше весить на диске и для обращений к нему нужно будет делать 3 чтения с диска, вместо 2 при последовательной.
Стоит заметить, что последовательная вставка в индекс это не всегда хорошо.
Если вставка преобладает перед чтением, то insert в разные части индекса лучше, чем последовательная в один блок. Т.к. это обеспечивает большую конкуренцию за общий ресурс и в итоге приведет к buffer busy wait. Специально для перемешивания данных используются реверсивные индексы (http://blog.skahin.ru/2015/04/oracle.html).
3. Поиск элемента
* начинаем с корня дерева (считываем его с диска) ( BPTree.indexScan )
* в блоке ветви бинарным поиском ищем элемент = искомому или первый больше его, если искомого нет в ветви (INode.getLoc)
* если нашли, то спускаемся налево, иначе если искомый элемент больше максимального в блоке ветви, то двигаемся направо (считывание с диска) (inner.children[idx])
* рекурсивно повторяем N раз = высота дерева - 1, пока не дойдем до листа (считывание с диска) (LNode leaf)
* в упорядоченном массиве блока листа бинарным поиском (считывание с диска) (leaf.getLoc)
Итого элемент будет найден за число считываний с диска = высоте дерева. Затраты CPU = высота дерева * log2(число строк в блоке)
3. При удалении данных из индекса, в целях ускорения, элемент физически не удаляется, а лишь помечается удаленным. Тем самым индекс не становится меньше весом.
Для устранения эффектов из п. 2 и 3 индекс необходимо периодически ребилдить rebuild
4. Операции min/max поиска также осуществляются за константное время = высоте дерева (операция index min/max scan) ( BPtree.getMin / BPtree.getMax )
5. Т.к. данные упорядоченные, то поиск нужного элемента внутри блока происходит с помощью бинарного поиска (LNode.getLoc).
Так что если сравнивать время доступа к таблице в 1 блок и к индексу в 1 блок: оба варианта дают 1 физическое чтение с диска, но поиск по индексу будет быстрей, т.к. для поиска элемента в упорядоченном массиве индекса log2(N) операций, а в неупорядоченной таблице - это всегда линейный поиск со стоимостью = N
6. Упорядоченность данных также позволяет искать данные по диапазону (BPTree.rangeScan):
* Находим стартовый элемент (Node.getLoc)
* Двигаемся по блоку вправо (while(leaf != null))
* Если дошли до конца блока, то переходим по ссылке на следующий ( leaf = leaf.next )
* доходим до элемента большего правой границы диапазона ( leaf.keys[i].compareTo(to_key) > 0 )
Это операция последовательного чтения массива, к сожалению, она никак не может быть распараллелена.
Также если в индексе после столбца, по которому идет сканирование по диапазаону, есть еще столбец, то он не сможет быть использован для доступа к нужному блоку индекса для старта, только для дофильтрации диапазона. Такой метод не уменьшит число физических чтений блоков индекса с диска.
7. null Значения
Oracle в отличии от других бд не хранит в индексе полностью пустые значения. Это значит что при поиске "idx_cold is null" не будет использоваться.
Это ограничение можно обойти, если создать индекс из 2 полей: нужного и любого другого. В качестве второго поля можно исопльзовать даже константу.
К примеру:
create index idx on tbl(col, 1);
В этом случае все значения колонки col, включая null, будут храниться в индексе и будет работать "col is null" сканирование.
8. index scip scan
9. Сжатые индексы
Не релизовывалось в данном классе.
Описание см. http://blog.skahin.ru/2015/04/oracle.html
10. Структура блока из 2 столбцов.
[ Flag Byte | Lock Byte | Length Byte 1 | Col1 | Length Byte 2 | Col 2 | Length Byte | rowid ]
Т.е. фактической разницы между индексом из 1 или 2 и более столбцов особо разницы нет.
12. Фактор кластеризации - соответствие последовательности элементов в индексе элементам в таблице. (BPtree.getClusterFactor)
Наилучший вариант, когда данные в таблице отсортированы на техже столбцах, что в индексе ( не важно прмямую или обратную). Тогда фактор кластеризации будет равен числу блоков в таблице.
Если же наоборот, то для чтения каждого элемента в индексе нужно считывать новый блок таблицы с диска, тогда фактор кластеризации = числу строк таблицы.
13. Index full scan - полное сканирование индекса (BPtree.fullScan)
14. Index Desc Scan - сканирование в обратном порядке
Индекс строится в прямом порядке и имеет ссылку в листовом блоке только на следующий.
То в случае запроса:
select * from tbl where idx_col between 7 and 9 order by idx_col desc;
Индекс также фильтруется как в п. 6, но обращения к таблице по rowid идет в обратном порядке, т.е. данные повторно не сортируются (order by idx_col desc), т.к. строки уже возвращаются из индекса в обратном порядке.
Исходный код B+дерева на java:
package BPTree; import java.util.concurrent.ThreadLocalRandom; public class BPTree<Key extends Comparable, Value> { //https://en.wikibooks.org/wiki/Algorithm_Implementation/Trees/B%2B_tree //корень дерева private Node root; //кол-во строк в блоке private final int rows_block; //высота дерева private int height = 1; //кол-во строк в индексе private int cnt = 0; public BPTree(int n) { rows_block = n; root = new LNode(); //первый блок и последний root.last = true; } //BPTree public void insert(Key key, Value value) { Split result = root.insert(key, value); if (result != null) { //разделяем корень на 2 части //создаем новый корень с сылками на лево и право INode _root = new INode(); _root.num = 1; _root.keys[0] = result.key; _root.children[0] = result.left; _root.children[1] = result.right; //уровень текущей ветки = высота предыдущей + 1 _root.level = result.level + 1; root = _root; //повышаем счетчик высоты дерева height++; } } //insert //index scan public Value indexScan(Key key) { Node node = root; //спускаемся по внутренним веткам, пока не дойдем до листа while (node instanceof BPTree.INode) { INode inner = (INode) node; int idx = inner.getLoc(key); node = inner.children[idx]; } //спустились до листа LNode leaf = (LNode) node; int idx = leaf.getLoc(key); //нашли ключ элемента в блоке //если последний элемент, то дополнительно проверим значение if (idx < leaf.num && leaf.keys[idx].equals(key)) { return leaf.values[idx]; } else { return null; } } //indexScan //index min scan public Value getMin() { Node node = root; //спускаемся по внутренним веткам налево, пока не дойдем до листа while (node instanceof BPTree.INode) { INode inner = (INode) node; node = inner.children[0]; } if( node.num == 0 ) return null; //спустились до листа LNode leaf = (LNode) node; return leaf.values[0]; } //getMin //index max scan public Value getMax() { Node node = root; //спускаемся по внутренним веткам направо, пока не дойдем до листа while (node instanceof BPTree.INode) { INode inner = (INode) node; node = inner.children [inner.num]; } if( node.num == 0 ) return null; //спустились до листа LNode leaf = (LNode) node; return leaf.values[leaf.num - 1]; } //getMax //index range scan - поиск по диапазону public Value[] rangeScan(Key from_key, Key to_key) { Node node = root; //спускаемся по внутренним веткам, пока не дойдем до листа while (node instanceof BPTree.INode) { INode inner = (INode) node; int idx = inner.getLoc(from_key); node = inner.children[idx]; } //спустились до листа LNode leaf = (LNode) node; int idx = leaf.getLoc(from_key); //нашли ключ элемента в блоке if (idx < leaf.num && leaf.keys[idx].compareTo(from_key) >= 0) { Value[] arr = (Value[]) new Object[cnt]; //двигаемся вправо, пока не найдем правую границу int cnt_arr = 0; do { //стартуем с найденного элемента for(int i = idx; i < leaf.num; i++) { if(leaf.keys[i].compareTo(to_key) > 0) { //возвращаем только нужное число элементов Value[] _arr = (Value[]) new Object[cnt_arr]; System.arraycopy(arr, 0, _arr, 0, cnt_arr); arr = null; return _arr; } arr[cnt_arr] = leaf.values[i]; cnt_arr++; } //последующие блоки читаем с 0 idx = 0; leaf = leaf.next; } while(leaf != null); Value[] _arr = (Value[]) new Object[cnt_arr]; System.arraycopy(arr, 0, _arr, 0, cnt_arr); arr = null; return _arr; } return null; } //rangeScan //index full scan public Value[] fullScan() { Node node = root; //спускаемся по внутренним веткам направо, пока не дойдем до листа while (node instanceof BPTree.INode) { INode inner = (INode) node; node = inner.children [0]; } if( node.num == 0 ) return null; Value[] arr = (Value[]) new Object[cnt]; //спустились до листа LNode leaf = (LNode) node; //последовательно идем по листам слева направо int cnt_arr = 0; do { System.arraycopy(leaf.values, 0, arr, cnt_arr, leaf.num); cnt_arr = cnt_arr + leaf.num; leaf = leaf.next; } while(leaf != null); return arr; } //fullScan //blevel - высота дерева -1 public int getBLevel() { return height - 1; } //getBLevel public int getCnt() { return cnt; } //getCnt //фактор кластеризации //идеально = число строк / число строк в блоке //плохо = число строк public int getClusterFactor() { int cluster_factor = 0; int prev_block = 0; int cur_block = 0; Object arr[] = new Integer[cnt]; arr = fullScan(); for(int i = 0; i < arr.length; i++) { int k_rowid = (Integer)arr[i]; cur_block = k_rowid / rows_block; if(prev_block != cur_block) { cluster_factor++; } prev_block = cur_block; } return cluster_factor; } //getClusterFactor public void dump() { System.out.println("blevel = " + getBLevel()); System.out.println("cnt = " + getCnt()); System.out.println("min[k] = " + getMin()); System.out.println("max[k] = " + getMax()); System.out.println("--------------------"); root.dump(); System.out.println("--------------------"); } //абстрактный класс блока: лист или ветвь abstract class Node { //кол-во элементов в блоке protected int num; //элементы в блоке protected Key[] keys; //высота ветви/листа int level; //последний блок ветви/листа boolean last = false; //поиск индекса элемента в массиве блока public int getLoc(Key key, boolean is_node) { //двоичный поиск в порядоченном массиве O=Log2N int lo = 0; int hi = num - 1; //пока левая и правая границы не встретятся while (lo <= hi) { //находим середину int mid = lo + (hi - lo) / 2; //если элемент меньше середины if (key.compareTo(keys[mid]) < 0) { //если текущий элемент больше, а следующий меньше, то возвращаем текущий if(mid == 0) return 0; if(mid > 0 && key.compareTo(keys[mid - 1]) > 0) return mid; //то верхняя граница - 1 = середина hi = mid - 1; } else if (key.compareTo(keys[mid]) > 0) { //если текущий элемент меньше, а следующий больше, то возвращаем следующий if(mid == num) return mid; if(mid < num - 1 && key.compareTo(keys[mid + 1]) < 0) return mid + 1; //если больше, то нижняя граница = середина + 1 lo = mid + 1; } else { //иначе нашли //для ветви возвращаем следующий за найденным элемент, т.к. ссылка идет налево if(is_node) return mid + 1; //для листы чисто найденный элемент return mid; } } return num; } //getLoc // возвращает null, если блок не нужно разделять, иначе информация о разделении abstract public Split insert(Key key, Value value); abstract public void dump(); } //Node //листовой блок дерева class LNode extends Node { //ссылки на реальные значения - строки таблицы final Value[] values = (Value[]) new Object[rows_block]; //ссылка на следующий блок LNode next; public LNode() { keys = (Key[]) new Comparable[rows_block]; level = 0; } //LNode public int getLoc(Key key) { return getLoc(key, false); } //getLoc //вставка элемента в листовой блок public Split insert(Key key, Value value) { // находим место для вставки int i = getLoc(key); //место вставки последний элемент, блок необходимо разбить на 2 части if (this.num == rows_block) { /* * Пример 50/50: * 3 1 2 3 4 5 --- mid = 5/2 = 2 snum = 4 - 2 = 2 -- уходит направо mid=2 --уходит налево keys[mid]=mid[3] = 3 --средний элемент, уходит наверх * */ //делим блок на 90/10 поумолчанию int mid = rows_block; //если вставка идет не в конец if(!this.last || i < mid) { //то делим блок 50/50 mid = (rows_block + 1) / 2; } //mid = (rows_block + 1) / 2; //кол-во элементов в правой части int sNum = this.num - mid; //новый правый листовой блок LNode sibling = new LNode(); sibling.num = sNum; //перемещаем в него половину элементов System.arraycopy(this.keys, mid, sibling.keys, 0, sNum); System.arraycopy(this.values, mid, sibling.values, 0, sNum); //делим ровно на полам, все элементы разойдутся налево или направо this.num = mid; //если сплитится последний блок, то помечаем последним правый if(this.last) { this.last = false; sibling.last = true; } //позиция в левом блоке if (i < mid) { this.insertNonfull(key, value, i); } else { //или в правой sibling.insertNonfull(key, value, i - mid); } //информируем блок ветви о разделении: {значение разделения, левый блок, правый блок, 0 уровень листа} //элемент разделения берем из правой части Split result = new Split(sibling.keys[0], this, sibling, level); //связываем текущий блок со следующим sibling.next = this.next; this.next = sibling; return result; } else { //блок не полон, вставляем элемент в i мето this.insertNonfull(key, value, i); return null; } } //вставка элемента в неполный листовой блок private void insertNonfull(Key key, Value value, int idx) { //смещаем все элементы массивов правее idx на 1 элемент System.arraycopy(keys, idx, keys, idx + 1, num - idx); System.arraycopy(values, idx, values, idx + 1, num - idx); //в освободившееся место вставляем элемент keys[idx] = key; values[idx] = value; //число элементов в блоке num++; //всего элементов в индексе cnt++; } public void dump() { if(last) { System.out.println("(last):"); } for (int i = 0; i < num; i++) { System.out.println(keys[i]); } } } //LNode //класс блока ветви class INode extends Node { final Node[] children = new BPTree.Node[rows_block + 1]; public INode() { keys = (Key[]) new Comparable[rows_block]; } //INode //поиск индекса для вставки в блоке-ветви public int getLoc(Key key) { return getLoc(key, true); } //getLoc //вставка элемента в ветвь public Split insert(Key key, Value value) { /* * Упрощенный вариант сплита, когда разделение идет сверху вниз, * что может привести к преждевременному росту дерева и как следствие дисковых чтений в бд. * В реальности разделение должно идти снизу вверх - это минимизирует рост дерева. * * */ //число элементов в блоке достигло предела - разделяем if (this.num == rows_block) { /* * Пример: * 2 1 3 4 (3 max) 3 1 2 4 5 (4 max) --- mid = 5/2 = 2 snum = 4 - 2 = 2 -- уходит направо mid-1=1 --уходит налево keys[mid-1]=mid[1] = 2 --средний элемент, уходит наверх * */ //середина int mid = (rows_block + 1) / 2; //создаем блок справа int sNum = this.num - mid; INode sibling = new INode(); sibling.num = sNum; sibling.level = this.level; //копируем в него половину значений System.arraycopy(this.keys, mid, sibling.keys, 0, sNum); //копируем дочерние элементы +1(?) System.arraycopy(this.children, mid, sibling.children, 0, sNum + 1); //в левой части будет -1 элемент, он уходит на верхний уровень this.num = mid - 1; //передаем информацию о разделении выше: {средний элемент, левая, правая ветвь} Split result = new Split(this.keys[mid - 1], this, sibling, this.level); //если элемент меньше середины, то вставляем в левую чать if (key.compareTo(result.key) < 0) { this.insertNonfull(key, value); } else { //иначе в правую sibling.insertNonfull(key, value); } //информируем вышестоящуюю ветвь о разделении, может ее тоже надо будет разделить return result; } else { //место под разбиение нижних еще есть - вставляем this.insertNonfull(key, value); return null; } } //insert private void insertNonfull(Key key, Value value) { //ищем индекс для вставки int idx = getLoc(key); //рекурсивный вызов для нижележайшей ветви Split result = children[idx].insert(key, value); //нижний блок пришлось разбить на 2 части if (result != null) { //вставка в крайнее правое место if (idx == num) { keys[idx] = result.key; // на нашем уровен становится 2 элемета-ветви //текущий будет ссылаться на левую чать разделенной дочерней части //а новый элемент снизу - на правую children[idx] = result.left; children[idx + 1] = result.right; num++; } else { //вставка в середину массива //смещаем все элементы вправа на 1 позицию System.arraycopy(keys, idx, keys, idx + 1, num - idx); System.arraycopy(children, idx, children, idx + 1, num - idx + 1); //аналогично children[idx] = result.left; children[idx + 1] = result.right; keys[idx] = result.key; num++; } } // result != null } //insertNonfull public void dump() { for (int i = 0; i < num; i++) { children[i].dump(); for(int j = 0; j < level; j++) System.out.print(" . "); System.out.println("> " + keys[i] + " ("+num+")"); } children[num].dump(); } } //INode //структура с информацией о разделении: значение разделения, левая и правая часть и уровень ветви class Split { public final Key key; public final Node left; public final Node right; public final int level; public Split(Key k, Node l, Node r, int h) { key = k; left = l; right = r; level = h; } } //Split public static void main(String[] args) { int rows_on_block = 3; BPTree t = new BPTree(rows_on_block); /*for(int i = 0; i <= 99; i++) { t.insert(i, i); }*/ /*for(int i = 99; i >= 0; i--) { t.insert(i, i); }*/ for(int i = 99; i >= 0; i--) { t.insert(ThreadLocalRandom.current().nextInt(0, 100), i); } // 0 1 2 3 4 5 6 7 8 9 10 11 12 13 /*Integer arr_tst[] = {2, 6, 3, 5, 1, 7, 8, 0, 27, 17, 99, 13, 1, 7}; for(int i = 0; i < arr_tst.length; i++) { t.insert(arr_tst[i], i); }*/ t.dump(); System.out.println("indexScan (5) = " + t.indexScan(5)); System.out.println("indexScan (6) = " + t.indexScan(6)); System.out.println("indexScan (4) = " + t.indexScan(4)); System.out.println("indexScan (1) = " + t.indexScan(1)); System.out.println("indexScan (99) = " + t.indexScan(99)); System.out.println("indexScan (100) = " + t.indexScan(100)); Object arr[] = new Integer[t.getCnt()]; arr = t.fullScan(); System.out.print("fullScan = "); for(int i = 0; i < arr.length; i++) { System.out.print((Integer)arr[i] + ", "); } System.out.println(" "); System.out.println("cluster_factor = " + t.getClusterFactor()); arr = t.rangeScan(2, 7); System.out.print("rangeScan(2,7) = "); for(int i = 0; i < arr.length; i++) { System.out.print((Integer)arr[i] + ", "); } } //main } //BPTree
Полный код класса и юнит тесты можно посмотреть здесь: https://github.com/pihel/java/blob/master/BPTree/
Подписаться на:
Сообщения (Atom)