- Order by сортировка
- BTree индекс
- Hash Join
- Bloom filter
- Lru cache
- Hash агрегация и приблизительный DISTINCT
Более редкая разновидность хэширования данных и вероятностной фильтрации данных - bloom filter
Раньше я уже описывал bloom filter в параллельных запросах со стороны разработчика бд: Oracle: оптимизация параллельных запросов, сегодня копнем немного глубже, с кодом bloom filter на java.
Bloom filter — это вероятностная структура данных, позволяющая компактно хранить множество элементов и проверять принадлежность заданного элемента к множеству. При этом существует возможность получить ложноположительное срабатывание (элемента в множестве нет, но структура данных сообщает, что он есть), но не ложноотрицательное.
Фильтр Блума может использовать любой объём памяти, заранее заданный пользователем, причём чем он больше, тем меньше вероятность ложного срабатывания.

Пример фильтра Блума с 18 бит в карте и 3 функциям хэширования, хранящего множество {x, y, z}. Цветные стрелки указывают на места в битовом массиве, соответствующие каждому элементу множества. Этот фильтр Блума определит, что элемент w не входит в множество, так как один из соответствующих ему битов равен нулю.
Основное предназначение - предфильтрация данных в источнике до передачи их в базу данных.
Принцип применения блум фильтра при join:
1. Левая таблица читается с диска и фильтруется (plan line = 3)
2. На основе левой таблицы создается битовая карта блум фильтра (:BF0000 plan line = 2)
3. Блум фильтр передается в источник правой таблицы (:BF0000 plan line = 4)
4. Строки правой таблицы фильтруются через блум фильтр (:BF0000 plan line = 5 - storage(SYS_OP_BLOOM_FILTER(:BF0000,"R"."L_ID")))
5. В бд передается уже частично отфильтрованная правая таблица
6. Выполняется join (plan line = 1)
create table l as select level as id, 'name_' || level as title, rpad('*', level) as pad from dual connect by level <= 50;
create table r as select rownum as id, mod(rownum, 50) as l_id, rpad('*', 20) as pad
from (select * from dual connect by level <= 1000 ) join (select * from dual connect by level <= 1000 ) on 1=1;
begin
DBMS_STATS.GATHER_TABLE_STATS(USER, 'L');
DBMS_STATS.GATHER_TABLE_STATS(USER, 'R');
end;
explain plan for
select *
from l
join r on l.id = r.l_id
WHERE l.title = 'name_5';
select * from table(dbms_xplan.display(format=>'ALLSTATS ALL ADVANCED'));
Plan hash value: 3967001914
----------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20000 | 1308K| 184 (20)| 00:00:01 |
|* 1 | HASH JOIN | | 20000 | 1308K| 184 (20)| 00:00:01 |
| 2 | JOIN FILTER CREATE | :BF0000 | 1 | 38 | 2 (0)| 00:00:01 |
|* 3 | TABLE ACCESS STORAGE FULL| L | 1 | 38 | 2 (0)| 00:00:01 |
| 4 | JOIN FILTER USE | :BF0000 | 1000K| 27M| 171 (15)| 00:00:01 |
|* 5 | TABLE ACCESS STORAGE FULL| R | 1000K| 27M| 171 (15)| 00:00:01 |
----------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - SEL$58A6D7F6
3 - SEL$58A6D7F6 / L@SEL$1
5 - SEL$58A6D7F6 / R@SEL$1
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("L"."ID"="R"."L_ID")
3 - storage("L"."TITLE"='name_5')
filter("L"."TITLE"='name_5')
5 - storage(SYS_OP_BLOOM_FILTER(:BF0000,"R"."L_ID"))
filter(SYS_OP_BLOOM_FILTER(:BF0000,"R"."L_ID"))
Детальное описание с кодом на java:
1. Блум фильтр состоит из массива бит произвольной длинны. В моем случае под битовый массив выделена переменная long в 64 бита:
package Hash;
import java.util.concurrent.ThreadLocalRandom;
public class BloomFilter {
//long переменная в 64бита под битовый массив
private long data;
//битов в битовой карте = числу битов в long
private int bit_array_size = Long.SIZE;
2. Определяется hash_num функций хэширования. На входе функции произвольная строка, на выходе номер бита в битовой карте для установки в 1.
//примесь для случайного хэширования
private int seed = ThreadLocalRandom.current().nextInt(1, bit_array_size);
//хэшировани = номер бита в битовом массиве
public long hashCode(String s, int hash_num) {
long result = 1;
//для каждого байта в строке
for (int i = 0; i < s.length(); ++i) {
//применяем хэш функцию под номером hash_num и обрезаем по маске
//простая хэш функция = ascii значение буквы * примесь * номер функции * хэш от предыдущей функции & обрезка по маске
//1 = (1 * 1 + 58)
//1 = ( 0001 * 0001 + 11 0001 ) & 1111 1111 1111 1111
result = ((hash_num + seed) * result + s.charAt(i)) & this.hashMask;
}
3. Устанавливаем биты в битовой карте для hash_nums хэш функций
//установить index бит в битовой карте
public void setBit(long index) {
//= битовая карта OR 1 смещенное влево на index
this.data = this.data | (1L << index );
} //setbit
//добавить элемент в блум фильтр
public void add(String s) {
//++ счетчик элементов
cnt++;
//для каждой хэш функции
for(int i = 1; i <= hash_nums; i++) {
//расчитаем номер индекса в битовой карте и установим его
long index = hashCode(s, i);
setBit(index);
}
} //add
4. Обратная операция - тестирование строки на вероятное наличие элемента в блум фильтре: хэшируем и проверяем бит в блум фильтре
//получить значение бита на index месте
public long getBit(long index) {
//=битовая карта смещенная вправо на index мест (>>> пустые места справа заполняются 0)
// & 01 - проверка только крайнего правого бита (все остальные игнорируются)
return ( this.data >>> index ) & 1;
} //getBit
//проверка наличия элемента в блум фильтре
public boolean test(String s) {
//для каждой хэш функции
for(int i = 1; i <= hash_nums; i++) {
//определяем номер бита в битовой карте
long index = hashCode(s, i);
//если хотябы одна проверка не прошла - элемента нет
if( getBit(index) == 0L ) return false;
}
//иначе элемент вероятно есть
return true;
} //test
Очевидно, чем больше битовая карта в блум фильтре, тем точней результат - меньше ложных срабатываний.
Зависимость определяется формулой:
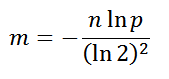
, где n — предполагаемое количество элементов хранящихся в фильтре-множестве, p — вероятность ложного срабатывания, m - число бит в карте
//вероятность ложного срабатывания
public double getFalsePossb() {
if(cnt == 0) return 0;
return 1 / Math.pow(Math.E, bit_array_size * Math.log(2) * Math.log(2) / cnt );
} //getFalsePossb
Вероятность ложного срабатывания от числа бит в карте и кол-ва элементов:

Также использование нескольких функции хэширования дает преимущество при достаточном размере блум фильтра:
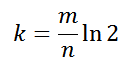
//оптимальное число функций хэширования
public int getOptimalFncCnt() {
if(cnt == 0) return 1;
return (int)Math.ceil( bit_array_size / cnt * Math.log(2) );
} //getOptimalFncCnt
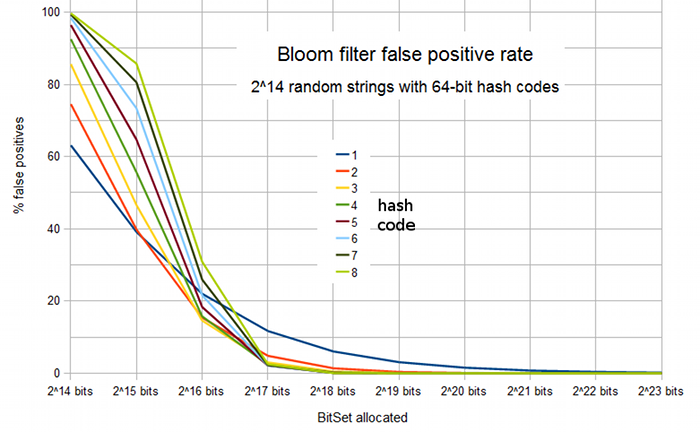
График вероятности ложного срабатывания от размера массива и числа функций хэширования:
Практическое применение Bloom фильтра в Oracle:
* Partition pruning - усечение просматриваемых партиций
На основе фильтра левой таблицы выбираются секции для сканирования из правой, что позволит не сканировать таблицу целиком.
* RAC - уменьшение сетевого трафика между кластерными нодами
Для уменьшения сетевого взаимодействия между кластерными нодами, если левую таблицу читает 1 нода, а правую нода 2.
Применение блум фильтра уменьшает размер пересылаемых данных правой таблицы из ноды 2 в ноду 1 до выполнения соединения.
* Exadata или Map reduce движок в качестве источника данных
Массовая параллельная обработка внутри exadata проходит быстрей, чем аналогичная операция внутри бд Oracle.
Из-за этого при наличии exadata Oracle стремится произвести максимальное число фильтрации в источнике до передачи в базу.
* In Memory хранилище данных
Аналогично exadata, inmemory движок может производить фильтрацию внутри себя и это будет быстрей, чем выполнять join на полном наборе данных.
При наличии таких данных Oracle стремится произвести максимум фильтрации до передачи данных в бд.
* Parallel - параллельные запросы
Взаимодействие параллеьлных поток происходит через координатор и если 1 поток читает левую таблицу, а 2 поток - правую, то выгодней и быстрей отфильтровать правую таблицу блум фильтром и передать в первый поток уже отфильтрованные данные.
* Гетерогенные запросы через дблинк (возможно)
Сетевое взаимодействие очень дорогое по сравнению с работой с памятью и даже диском. Из-за этого было бы выгодно отфильтровать правую таблицу на удаленной бд до ее передачи в нашу.
Полную реализацию блум фильтра можно видеть здесь: https://github.com/pihel/java/blob/master/Hash/BloomFilter.java
Комментариев нет:
Отправить комментарий