Предоставления для мониторинга нагрузки на субд sap hana:
суббота, 19 августа 2017 г.
вторник, 15 августа 2017 г.
HIVE: Своя быстрая функция замен встроенной
Один из вариантов ускорить HIVEQL запрос - это переписать встроенную аналитическую функцию на свой упрощенный вариант.
К примеру функция ROW_NUMBER(OVER PARTITION BY c1 ORDER BY c2) имеет достаточно сложную реализацию (github) только для того чтобы посчитать номер строки в группе.
Пример запроса с row_number:
create table tmp_table stored as orc as select v.material, v.client_id, row_number() over (partition by v.client_id order by v.clientsum desc, v.checkcount desc) as rn from pos_rec_itm_tst v;
Можно реализовать значительно упрощенную версию подсчета номера строки в группе.
На вход функции Rank.evaluate подаем значение группы key (то что было в partition by) и инкрементируем значение счетчика counter.
Если приходит новая группа, то счетчик сбрасывается на 0, а в переменную группы "this.last_key" записывается значение новой группы:
package com.example.hive.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
public final class Rank extends UDF{
private int counter;
private String last_key;
public int evaluate(final String key){
if ( !key.equals(this.last_key) ) {
this.counter = 0;
this.last_key = key;
}
return (++this.counter);
}
}
Понятно, что для правильной работы этой функции набор данных нужно предварительно отсортировать по группе партицирования "partition by", а потом по остальным полям "order by".Пример запроса с собственной функцией:
create table tmp_table stored as orc as select v.material, v.client_id, myrank(v.client_id) as rn from ( SELECT client_id, clientsum, checkcount, material FROM pos_rec_itm_tst DISTRIBUTE BY client_id SORT BY clientsum desc, checkcount desc ) v;Дополнительно сортировку в HIVE можно ускорить, если распараллелить мапперы по полю партицирования "partition by", а внутри этих групп сортировать по полям из "order by".
За счет параллельности мы опять же ускорим сортировку.
Чтобы создать такую функцию в HIVE нужно скомпилировать ее из java исходников:
$> /путь_до_java_который_используется_в_hive/bin/javac -classpath /путь_до_hive/lib/hive/lib/hive-serde-1.7.jar:/путь_до_hive/lib/hive/lib/hive-exec.jar:/путь_до_hadoop/lib/hadoop/client-0.20/hadoop-core.jar -d /путь_куда_компилим /путь_до_программы.java $> /путь_до_java_который_используется_в_hive/bin/jar -cf название_jar_программы.jar com/example/hive/udf/название_класса.class
запускаем hive и регистрируем наш jar , как функцию с произвольным названием:
hive> add jar Rank.jar; hive> create temporary function myrank as 'com.example.hive.udf.Rank';
Такое небольшое изменение ускорит выполнение запроса на 10-20%.
среда, 5 апреля 2017 г.
Oracle: columnar compression в exadata и inmemory
В связи с развитием баз данных в области колоночных inmemory хранилищ, хотел бы осветить развитие опции компрессии в субд Oracle.
Представляет из себя дедублицирование данных.
При Update строка становится мигрированной и хранится уже не сжатой.
Oltp compression – работает при любых вставках и требует наличия опции advanced compression.
Представляет из себя дедублицирование данных.
При не «direct path» строка сначала вставляется несжатой, при накоплении % несжатых записей в блоке = PCTFREE, блок сжимается и т.д.:

При Update строка становится мигрированной и хранится сначала не сжатой, но потом при накоплении PCTFREE % несжатых записей, блок аналогично сжимается.
работает только с «Exadata или Oracle ZFS Storage Appliance или either the Pillar Axiom или Oracle FS1 storage array».
Oracle хранит компрессированную колонку в виде связки блоков (как мигрированная строка), что оставляет возможность быстрого доступа к колонке по rowid и создание индексов!.
Также требуется direct path (append) вставка.
Внутреннее устройство:
Строки данных бьются на compression unit (cu) – это достаточно большая сущность (32 КБ) и со стороны Oracle рассматривается как 1 блок.

Детальная структура CU:

CU в заголовке содержит указатели на колонки. А блоки внутри CU указатели на строки.
Т.к. все строки поделены на CU, внутри которых последовательно хранятся колонки, то добавление колонок к запросу не увеличивает число чтений (даже если строки из разных CU, число чтений будет кратно число блоков в CU * кол-во запрашиваемых CU):
Чтение 1 блока дает 417 чтений:
И чтение из 2 разных блоков тоже дает 417 чтений, т.к. оба этих блока входят в 1 CU:

Поддержка DML:
- Блокировка по умолчанию происходит на уровне CU. Если нужна блокировка на уровне строки, то таблицу нужно создавать с директивой «ROW LEVEL LOCKING», которая расширяет заголовок CU под флаги блокировок всех строк всех блоков.
- При обновлении строки, она мигрирует в другой блок и помечается сжатой как OLTP, в не зависимости от степени сжатия раньше (см. описание выше)
Сжатие колонок
Обычные способы сжатия, а не алгоритмы дедубликации:
Т.к. HCC заточено на хранилища данных, то максимальный выигрыш дают смарт сканы, т.к. разархивация происходит на стороне exadata cells. В случае индексного доступа разархивация происходит уже в БД (причем всего CU!):
Смарт скан, отрицательный offloading - возвращено больше, чем считано:
Чтение по индексу - считывается весь CU, а разархивация происходит внутри субд:
Загонять данные в колонки нужно вручную.
В inmemory можно поместить часть столбцов или разную степень для разных колонок.
Размер IMCU = 1МБ ( blogs.oracle.com ) см. imcu_addr.v$im_header

Данные в IMCU всегда хранятся в порядке вставки (rowid) - docs.oracle.com
Пример:
Данные из колонки «prod_id» фильтруются, в результате чего определяются позиции на которых находятся искомые данные. Т.к. данные в колонках лежат в том же порядке (включая null), то по этим номерам позиций забираются соответствующие значения из связанных колонок (time_id, chanel_id)
хэш массив уникальных значений в CU (в виде чисел)
min/max значение в колонке CU
«IM storage index» - для отфильтровывания CU
IMCU index хранятся прямо в заголовке CU.
SMU (Snapshot Metadata Unit) = 64КБ – метаданные о IMCU - информация о инвалидации данных в IMCU при DML (транзакционный журнал).
Для DML по прежнему используется буферный кэш, но в SMU помещается информация, что rowid был инвалидирован.
Т.е. чем больше DML, тем хуже работает IM
Repopulation – периодическое обновление измененных данных в IMCU из буферного кэша (при накоплении определенного объема). На время этой операции IMCU отключаются, используется стандартный механизм доступа.

Ручной запуск:
При exchange partition чтобы не потерять данные IM нужно собрать данные src таблицы в IM. Тогда обмен произойдет как у таблицы, так и у IM хранилища.
При direct path (+append) вставке происходит автоматическая фоновая репопуляция.
IM expression unit
В IM кроме обычных колонок могут хранится виртуальные выражения (как колонки, там и предрасчитанные на основе статистики вызова - «IM expression statistic store»), они будут также обновляться при repopulation.
IM expression statistic store
Дополнительное сохранение агрегированных данных SELECT, WHERE, GROUP BY если они часто вызываются и требуют больших расходов на расчет.
SIMD – векторная обработка колонок
Т.к. данные для фильтрации хранятся в виде колонки-вектора, то для фильтрации можно использовать векторные возможности CPU.
Векторная операция – это когда за 1 такт процессора происходит сравнение не одной переменной, а целого вектора значений (к примеру 8)

Раньше эта технология часто использовалась в графике, например при работе с RGB значениями, цвет пикселя можно было сменить за 1 такт CPU, теперь эти технологии нашли применение и в СУБД.
Компрессия:
* «MEMCOMPRESS FOR QUERY LOW» - алгоритм по умолчанию
Похоже на дедублицирование: словарь + обнаружение повторов + замена повтором на бит ссылку
(oracle.com/technetwork )
* «MEMCOMPRESS FOR CAPACITY LOW» - Используется проприетарный алгоритм OZIP, как расширение поверх «MEMCOMPRESS FOR QUERY LOW». Нужно разжатие перед выполнением WHERE, но может выполняться прямо на CPU (нужны специальные сервера с SQL in Silicon)
IM JOIN
Обычный джойн выполняется так:

Т.е. большая часть работы — это преобразование колоночного вида в строковое хранилище pga.
Над join можно произвести первую оптимизацию — bloom filter, т. е. испольлзуя данные 1 таблицы откинуть лишние CU еще до join.
Для устранения необходимости преобразования колоночного вида в строковый можно подготовить что-то типа join индекса в IM:
В индексе сохраняются сочетания значений «Local dictionary CU» нужных колонок таблиц, где значения = указатели на нужные CU.
В итоге JOIN будет выполняться как фильтр большей таблицы по данным меньшей:
* фильтруем колонку левой таблицы
* получаем цифровые значения строк левой таблицы из “Local dictionary CU”
* сохраняем этот массив в PGA
* применяем фильтр к правой таблице на основе нашего «INMEMORY JOIN GROUP» где хранится связка левых CU с правыми CU

В итоге получается выполнение join без преобразования колонок в строки и фильтрация идет по обычному массиву (не хэш), т. е. без потребления дополнительного CPU для хэширования и проблемы хэш массива: устранения коллизий.
IM Vector Group BY
IM Vector group by есть общее со star transformation – преобразование JOIN в фильтрацию фактовой таблицы измерениями:
* фильтруем колонку левой таблицы
* Создаем массив уникальных значений левой таблицы: 0 — нет значения, 1,2,N существующие уникальные значения
* созданные массивы в векторном режиме применяются над фактовой таблицой.
План будет выглядеть так:
IM RAC
Можно продублировать IMCU на всех нодах «DUPLICATE ALL» или разделить таблицу (DISTRIBUTE ) — часть на 1 ноде, часть на другой:
* по партициям «DISTRIBUTE BY PARTITION »
* по диапазону rowid “DISTRIBUTE BY ROWID RANGE”
Строчные сжатия
Basic compression – работает только при direct path (append) вставкеПредставляет из себя дедублицирование данных.
При Update строка становится мигрированной и хранится уже не сжатой.
Oltp compression – работает при любых вставках и требует наличия опции advanced compression.
Представляет из себя дедублицирование данных.
При не «direct path» строка сначала вставляется несжатой, при накоплении % несжатых записей в блоке = PCTFREE, блок сжимается и т.д.:
При Update строка становится мигрированной и хранится сначала не сжатой, но потом при накоплении PCTFREE % несжатых записей, блок аналогично сжимается.
Колоночное сжатие
HCC - hybrid columnar compressionработает только с «Exadata или Oracle ZFS Storage Appliance или either the Pillar Axiom или Oracle FS1 storage array».
Oracle хранит компрессированную колонку в виде связки блоков (как мигрированная строка), что оставляет возможность быстрого доступа к колонке по rowid и создание индексов!.
Также требуется direct path (append) вставка.
Внутреннее устройство:
Строки данных бьются на compression unit (cu) – это достаточно большая сущность (32 КБ) и со стороны Oracle рассматривается как 1 блок.
Детальная структура CU:
CU в заголовке содержит указатели на колонки. А блоки внутри CU указатели на строки.
Т.к. все строки поделены на CU, внутри которых последовательно хранятся колонки, то добавление колонок к запросу не увеличивает число чтений (даже если строки из разных CU, число чтений будет кратно число блоков в CU * кол-во запрашиваемых CU):
Чтение 1 блока дает 417 чтений:
select /*+ MONITOR */ id, num_1000000 from t_qh where id in( 5123456);
И чтение из 2 разных блоков тоже дает 417 чтений, т.к. оба этих блока входят в 1 CU:
select /*+ MONITOR */ id, num_1000000 from t_qh where id in( 5123456, 6114557 );
Поддержка DML:
- Блокировка по умолчанию происходит на уровне CU. Если нужна блокировка на уровне строки, то таблицу нужно создавать с директивой «ROW LEVEL LOCKING», которая расширяет заголовок CU под флаги блокировок всех строк всех блоков.
- При обновлении строки, она мигрирует в другой блок и помечается сжатой как OLTP, в не зависимости от степени сжатия раньше (см. описание выше)
Сжатие колонок
Обычные способы сжатия, а не алгоритмы дедубликации:
- Query Low – LZO (4x)
Данные перед вставкой не сортируются - Query High – gzip (6x)
Во всех других случаях данных сортируются в рамках одного CU, чтобы достичь большей компрессии (по одному из столбцов?) - Archive Low – gzip high (7x)
- Archive High – bzip2 (12x)
Т.к. HCC заточено на хранилища данных, то максимальный выигрыш дают смарт сканы, т.к. разархивация происходит на стороне exadata cells. В случае индексного доступа разархивация происходит уже в БД (причем всего CU!):
Смарт скан, отрицательный offloading - возвращено больше, чем считано:
select /*+ monitor */ count(DISTINCT num_1000), count(DISTINCT num_10), count(DISTINCT num_1000000) from t_qh;
Чтение по индексу - считывается весь CU, а разархивация происходит внутри субд:
select /*+ MONITOR */ id, num_1000000 from t_qh where id in( 5123456);
Inmemory HCC
Oracle хранит данные сразу в 2 форматах: строковый и колоночный. Это могут быть как таблицы, так и matview на наборе таблиц.Загонять данные в колонки нужно вручную.
В inmemory можно поместить часть столбцов или разную степень для разных колонок.
Размер IMCU = 1МБ ( blogs.oracle.com ) см. imcu_addr.v$im_header
Данные в IMCU всегда хранятся в порядке вставки (rowid) - docs.oracle.com
Пример:
SELECT cust_id, time_id, channel_id FROM sales WHERE prod_id =5;
Данные из колонки «prod_id» фильтруются, в результате чего определяются позиции на которых находятся искомые данные. Т.к. данные в колонках лежат в том же порядке (включая null), то по этим номерам позиций забираются соответствующие значения из связанных колонок (time_id, chanel_id)
Основные понятия IM HCC
Local dictionary CUхэш массив уникальных значений в CU (в виде чисел)
min/max значение в колонке CU
«IM storage index» - для отфильтровывания CU
IMCU index хранятся прямо в заголовке CU.
SMU (Snapshot Metadata Unit) = 64КБ – метаданные о IMCU - информация о инвалидации данных в IMCU при DML (транзакционный журнал).
Для DML по прежнему используется буферный кэш, но в SMU помещается информация, что rowid был инвалидирован.
Т.е. чем больше DML, тем хуже работает IM
Repopulation – периодическое обновление измененных данных в IMCU из буферного кэша (при накоплении определенного объема). На время этой операции IMCU отключаются, используется стандартный механизм доступа.
Ручной запуск:
EXEC DBMS_INMEMORY.POPULATE('SH', 'CUSTOMERS');
При exchange partition чтобы не потерять данные IM нужно собрать данные src таблицы в IM. Тогда обмен произойдет как у таблицы, так и у IM хранилища.
При direct path (+append) вставке происходит автоматическая фоновая репопуляция.
IM expression unit
В IM кроме обычных колонок могут хранится виртуальные выражения (как колонки, там и предрасчитанные на основе статистики вызова - «IM expression statistic store»), они будут также обновляться при repopulation.
IM expression statistic store
Дополнительное сохранение агрегированных данных SELECT, WHERE, GROUP BY если они часто вызываются и требуют больших расходов на расчет.
SIMD – векторная обработка колонок
Т.к. данные для фильтрации хранятся в виде колонки-вектора, то для фильтрации можно использовать векторные возможности CPU.
Векторная операция – это когда за 1 такт процессора происходит сравнение не одной переменной, а целого вектора значений (к примеру 8)
Раньше эта технология часто использовалась в графике, например при работе с RGB значениями, цвет пикселя можно было сменить за 1 такт CPU, теперь эти технологии нашли применение и в СУБД.
Компрессия:
* «MEMCOMPRESS FOR QUERY LOW» - алгоритм по умолчанию
Похоже на дедублицирование: словарь + обнаружение повторов + замена повтором на бит ссылку
(oracle.com/technetwork )
* «MEMCOMPRESS FOR CAPACITY LOW» - Используется проприетарный алгоритм OZIP, как расширение поверх «MEMCOMPRESS FOR QUERY LOW». Нужно разжатие перед выполнением WHERE, но может выполняться прямо на CPU (нужны специальные сервера с SQL in Silicon)
IM JOIN
SELECT v.year, v.name, s.sales_price FROM vehicles v, sales s WHERE v.name = s.name;
Обычный джойн выполняется так:
Т.е. большая часть работы — это преобразование колоночного вида в строковое хранилище pga.
Над join можно произвести первую оптимизацию — bloom filter, т. е. испольлзуя данные 1 таблицы откинуть лишние CU еще до join.
Для устранения необходимости преобразования колоночного вида в строковый можно подготовить что-то типа join индекса в IM:
CREATE INMEMORY JOIN GROUP deptid_jg (hr.employees(department_id),hr.departments(department_id));
В индексе сохраняются сочетания значений «Local dictionary CU» нужных колонок таблиц, где значения = указатели на нужные CU.
В итоге JOIN будет выполняться как фильтр большей таблицы по данным меньшей:
* фильтруем колонку левой таблицы
* получаем цифровые значения строк левой таблицы из “Local dictionary CU”
* сохраняем этот массив в PGA
* применяем фильтр к правой таблице на основе нашего «INMEMORY JOIN GROUP» где хранится связка левых CU с правыми CU
В итоге получается выполнение join без преобразования колонок в строки и фильтрация идет по обычному массиву (не хэш), т. е. без потребления дополнительного CPU для хэширования и проблемы хэш массива: устранения коллизий.
IM Vector Group BY
SELECT c.customer_id, s.quantity_sold, s.amount_sold FROM customers c, sales s WHERE c.customer_id = s.customer_id AND c.country_id = 'FR';
IM Vector group by есть общее со star transformation – преобразование JOIN в фильтрацию фактовой таблицы измерениями:
* фильтруем колонку левой таблицы
* Создаем массив уникальных значений левой таблицы: 0 — нет значения, 1,2,N существующие уникальные значения
* созданные массивы в векторном режиме применяются над фактовой таблицой.
План будет выглядеть так:
SQL_ID 0yxqj2nq8p9kt, child number 0
-------------------------------------
SELECT t.calendar_year, p.prod_category, SUM(quantity_sold) FROM
times t, products p, sales f WHERE t.time_id = f.time_id AND
p.prod_id = f.prod_id GROUP BY t.calendar_year, p.prod_category
Plan hash value: 2377225738
------------------------------------------------------------------------------------------------------
|Id| Operation | Name |Rows|Bytes|Cost(%CPU)|Time|Pstart|Pstop|
------------------------------------------------------------------------------------------------------
| 0|SELECT STATEMENT | | | |285(100)| | | |
| 1| TEMP TABLE TRANSFORMATION | | | | | | | |
| 2| LOAD AS SELECT |SYS_TEMP_0FD9D6644_11CBE8| | | | | | |
| 3| VECTOR GROUP BY | | 5| 80 | 3(100)|00:00:01| | |
| 4| KEY VECTOR CREATE BUFFERED | :KV0000 |1826|29216| 3(100)|00:00:01| | |
| 5| TABLE ACCESS INMEMORY FULL | TIMES |1826|21912| 1(100)|00:00:01| | |
| 6| LOAD AS SELECT |SYS_TEMP_0FD9D6645_11CBE8| | | | | | |
| 7| VECTOR GROUP BY | | 5| 125 | 1(100)|00:00:01| | |
| 8| KEY VECTOR CREATE BUFFERED | :KV0001 | 72| 1800| 1(100)|00:00:01| | |
| 9| TABLE ACCESS INMEMORY FULL | PRODUCTS | 72| 1512| 0 (0)| | | |
|10| HASH GROUP BY | | 18| 1440|282 (99)|00:00:01| | |
|11| HASH JOIN | | 18| 1440|281 (99)|00:00:01| | |
|12| HASH JOIN | | 18| 990 |278(100)|00:00:01| | |
|13| TABLE ACCESS FULL |SYS_TEMP_0FD9D6644_11CBE8| 5| 80 | 2 (0)|00:00:01| | |
|14| VIEW | VW_VT_AF278325 | 18| 702 |276(100)|00:00:01| | |
|15| VECTOR GROUP BY | | 18| 414 |276(100)|00:00:01| | |
|16| HASH GROUP BY | | 18| 414 |276(100)|00:00:01| | |
|17| KEY VECTOR USE | :KV0000 |918K| 20M|276(100)|00:00:01| | |
|18| KEY VECTOR USE | :KV0001 |918K| 16M|272(100)|00:00:01| | |
|19| PARTITION RANGE ALL | |918K| 13M|257(100)|00:00:01|1|28|
|20| TABLE ACCESS INMEMORY FULL| SALES |918K| 13M|257(100)|00:00:01|1|28|
|21| TABLE ACCESS FULL |SYS_TEMP_0FD9D6645_11CBE8| 5 | 125| 2 (0)|00:00:01| | |
------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
11 - access("ITEM_10"=INTERNAL_FUNCTION("C0") AND "ITEM_11"="C2")
12 - access("ITEM_8"=INTERNAL_FUNCTION("C0") AND "ITEM_9"="C2")
Note
-----
- vector transformation used for this statement
IM RAC
Можно продублировать IMCU на всех нодах «DUPLICATE ALL» или разделить таблицу (DISTRIBUTE ) — часть на 1 ноде, часть на другой:
* по партициям «DISTRIBUTE BY PARTITION »
* по диапазону rowid “DISTRIBUTE BY ROWID RANGE”
воскресенье, 26 марта 2017 г.
Решение bigdata задач на Hadoop mapreduce
Hadoop
Набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов.Ссылка на установку: http://www.cloudera.com/content/www/en-us/downloads.html
Hadoop состоит из 2 основных частей hdfs и map reduce. Рассмотрим подробней.
Hdfs
- распределенная файловая система. Это значит, что данные файла распределены по множеству серверов.* hdfs лучше работает с небольшим числом больших файлов/блоков
* один раз записали, много раз считали
* можно только целиком считать, целиком очистить или дописать в конец (нельзя с середины)
* файлы бьются на блоки split (к примеру 64мб)
** размер блока выбирается так, чтобы нивилировать время передачи блока по сети (если сеть быстрая, то блок можно поменьше, если медленная, то больше)
* все блоки реплицируются с фактором 3 поумолчанию (хранятся в 3 копиях на разных серверах)
** это обеспечивает высокую пропускную способность, но не скорость реакции
Hdfs java api
Пример программы копирующей один файл в другой:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.InputStream;
Path source_path = new Path(args[0]);
Path target_path = new Path(args[1]);
Configuration conf = new Configuration();
FileSystem source_fs = FileSystem.get(source_path.toUri(), conf);
FileSystem target_fs = FileSystem.get(target_path.toUri(), conf);
//доступ к нескольким файлам по маскам
//FileStatus [] files = fs.globStatus(glob);
//?, *, [abc], [^a], {ab, cd}
FSDataOutputStream output = target_fs.create(target_path);
InputStream input = null;
try{
input = source_fs.open(source_path);
IOUtils.copyBytes(input, output, conf);
} finally {
IOUtils.closeStream(input);
IOUtils.closeStream(output);
}
Парадигма map reduce
1. input file: split 1 + split 2 + split 3 (блоки файла). Каждый сплит хранится на своем сервере кластера.2. mapper:
* на каждый split N создается worker для обработки
* worker выполяется на сервере, где находится блок
* workerы не могут обмениваются между собой данными
** т.е. mapper подходит для независимых данных, которые легко побить на части.
зависимые данные (типа архива zip) нельзя побить на части в mapper:
все блоки (split) будут переданы в один mapper
* в случае ошибки процесс рестратует на другой копии блока hdfs
* combine - (необязательный шаг) - reducer внутри mappera агрегирующие данные в меньшее число данных (ключ менять нельзя)
** агрегирует только данные одного маппера
* partition - (необязательный шаг) - определение куда отправится ключ (поумолчанию hash(k) mod N , где N - число reducer )
3. результат mapper записывается в виде ключ значение {k->v} в циклический буфер в памяти, конец списка пишется на локальный диск сервера с worker
** это сделано в целях производительности, чтобы не реплицировать
** но в случае ошибки, данные нельзя будет восстановить и потребует рестартовать mapper
4. данные из {k->v} расходятся на сервера reduccer на основе ключа.
Т.е. данные с разных mapperов но с одним key попадут в один reducer
5. Результат reducer складываются в hdfs. Число файлов = число reducer
Hadoop streaming
Инструмент для быстрого прототипирования map reduce задач.можно писать python программы заготовки, общение маппера с редусером проиходит чреез stdin/out.
Данные передаются как текст разделенный табом
word count
#!/usr/bin/python
import sys
for line in sys.stdin:
for token in line.strip().split(" "):
if token: print(token + '\t1')
#!/usr/bin/python
import sys
(lastKey, sum)=(None, 0)
for line in sys.stdin:
(key, value) = line.strip().split("\t")
if lastKey and lastKey != key:
print (lastKey + '\t' + str(sum))
(lastKey, sum) = (key, int(value))
else:
(lastKey, sum) = (key, sum + int(value))
if lastKey:
print (lastKey + '\t' + str(sum))
Запуск:
hadoop jar $HADOOP_HOME/hadoop/hadoop-streaming.jar \ -D mapred.job.name="WordCount Job via Streaming" \ -files countMap.py, countReduce.py \ -input text.txt \ -output /tmp/wordCount/ \ -mapper countMap.py \ -combiner countReduce.py \ -reducer countReduce.py
Java source code example
Программа подсчитывающая число слов в hdfs файле.word count
public class WordCountJob extends Configured implements Tool {
static public class WordCountMapper extends Mapper < LongWritable, Text, Text, IntWritable > {
private final static IntWritable one = new IntWritable(1);
private final Text word = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//разбиваем строку (key) на слова и передаем пару: слово, 1
StringTokenizertokenizer = new StringTokenizer(value.toString());
while (tokenizer.hasMoreTokens()) {
text.set(tokenizer.nextToken());
context.write(text, one);
}
} //map
} //WordCountMapper
static public class WordCountReducer extends Reducer < Text, IntWritable, Text, IntWritable > {
@Override
protected void reduce(Text key, Iterable < IntWritable > values, Context context) throws IOException, InterruptedException {
//в редусер приходят все единицы от одного слова
intsum = 0;
for (IntWritable value: values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
} //reduce
} //WordCountReducer
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf(), "WordCount");
//класс обработчик
job.setJarByClass(getClass());
//путь до файла
TextInputFormat.addInputPath(job, new Path(args[0]));
//формат входных данных (можно отнаследовать и сделать собственный)
job.setInputFormatClass(TextInputFormat.class);
//классы мапперов, редусееров, комбайнеров и т.д.
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setCombinerClass(WordCountReducer.class);
//выходной файл
TextOutputFormat.setOutputPath(job, new Path(args[1]));
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
} //run
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run( new WordCountJob(), args);
System.exit(exitCode);
} //main
} //WordCountJob
Такая программа будет тратить все время на передачу данных от маппера к редусеру.
Её можно усовершенствовать несколькими способами:
* Сделать комбайнер - чтобы данные из одного маппера были сагрегированы там.
- не обязательно вызывается
+/- агрегирует данные только одного вызова маппера (одной строки)
* хэш аггегировать внутри маппера:
+ обязательно выполнится
+/- агрегирует данные только одного вызова маппера (одной строки)
- нужно следить за размером хэш массива
* хэш массив сверху маппера, а внутри маппера обрабатывать
+ обязательно выполнится
+ агрегирует все вызовы маппера (сплита)
- нужно следить за размером хэш массива
Sql операции
Разность (minus) и другое по аналогии
// на вход подаются элементы из двух множеств A и B
class Mapper
method Map(rowkey key, value t)
Emit(value t, string t.SetName) // t.SetName либо ‘A‘ либо ‘B'
class Reducer
// массив n может быть [‘A'], [‘B'], [‘A' ‘B‘] или [‘B', ‘A']
method Reduce(value t, array n)
if n.size() = 1 and n[1] = 'A'
Emit(value t, null)
* hash join
class Mapper
method Initialize
H = new AssociativeArray : join_key -> tuple from A //хэшируем меньшую таблицу целиком в память
A = load()
for all [ join_key k, tuple [a1, a2,...] ] in A
H{k} = H{k}.append( [a1, a2,...] )
method Map(join_key k, tuple B)
for all tuple a in H{k} //ищем в A соответствие ключа из B
Emit(null, tuple [k a B] ) //если нашли, то записываем
Операции на графах
оптимальное представление в виде списка смежности, т.к. матрица смежности занимает слишком много места* поиск кратчайшего пути
** обычный алгоритм - дейкстра
** поиск в ширину (bfs)
на невзвешенном графе (нет связей назад):
- Останавливаемся, как только расстояния до каждой вершины стало известно
- Останавливаемся, когда пройдет число итераций, равное диаметру графа
на взвешенном графе (есть обратные связи):
- Останавливаемся, после того, как расстояния перестают меняться
* PR = a (1/N) + (1-a)* SUM( PR(i) / C(i) )
** N - начальное число точек в графе
** C - число исходящих точек
** a - вероятность случайного перехода
** pr решается только приблизительно:
- останавливаем, когда значения перестают меняться
- фиксированное число итерации
- когда изменение значение меньше определенного числа
* проблемы
** необходимость передавать весь граф между всеми задачами
** итеративный режим, т.е. переход на следующий этап, когда все параллельные задачи выполнятся
* оптимизации:
** inmemory combining - агрегируем сообщения в общем массиве
** партицирование - смежные точки оказались на одном маппере
** структуру графа читать из hdfs, а не передавать + партицирование
Высокоуровневые языки поверх hdfs или hadoop:
Pig
высокоуровневый язык + компилятор в mapreduceиспользуется для быстрого написания типовых map-reduce задач
основные составляющие:
* field - поле
* tuple - кортеж (1, "a", 2)
* bag - коллекция кортежей {(), ()}
** коллекции могут содержать разное кол-во полей в кортеже (также они могут быть разных типов)
word count:
input_lines = LOAD 'file-with-text' AS (line:chararray); words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word; filtered_words = FILTER words BY word MATCHES '\\w+'; word_groups = GROUP filtered_words BY word; word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word; ordered_word_count = ORDER word_count BY count DESC; STORE ordered_word_count INTO ‘number-of-words-file';
join
//Загрузить записи в bag #1
posts = LOAD 'data/user-posts.txt' USING PigStorage(',') AS (user:chararray,post:chararray,date:long);
//Загрузить записи в bag #2
likes = LOAD 'data/user-likes.txt' USING PigStorage(',') AS (user:chararray,likes:int,date:long);
userInfo = JOIN posts BY user, likes BY user;
DUMP userInfo;
Hive
sql подобный язык hivesql поверх hadoopосновные составляющие - как в бд
метаданные могут храниться в mysql /derby
* создание таблицы
hive> CREATE TABLE posts (user STRING, post STRING, time BIGINT) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ',' > STORED AS TEXTFILE;
* при нарушении схемы ошибки не будет, вставится NULL
join
hive> INSERT OVERWRITE TABLE posts_likes > SELECT p.user, p.post, l.count > FROM posts p JOIN likes l ON (p.user = l.user);
word count
CREATE TABLE docs (line STRING); LOAD DATA INPATH 'docs' OVERWRITE INTO TABLE docs; CREATE TABLE word_counts AS SELECT word, count(1) AS count FROM (SELECT explode(split(line, '\s')) AS word FROM docs) w GROUP BY word ORDER BY word;
Nosql
* Масштабирование:** мастер-слейв: распределение нагрузки cpu, io остается общим
** шардинг: деление данных таблицы по серверам: распределение io, cpu Общее
* cap theorem - достигается только 2 из 3
** consistency - непротиворечивость
Чаще всего жертвует строгой целостностью в текущий момент, на целостность в конечном счете
** aviability - доступность
** partioning - разделение данных на части
* типы:
** ключ-значение
** колоночная
** документоориентировання
** графовая
Hbase
- поколоночная база** строки в таблицах шардируются на сервера
*** строки хранятся в отстортированном виде, чтобы можно было искать по серверам
*** список шардов хранится в HMaster
через него определяется сервер для чтений, а дальше чтение идет уже напряму с него миную hmaster
! возможная точка отказа
** столбцы объединяются в column family
*** каждая такая группа сохраняется также в отдельный файл
*** для всей группы задается степень сжатия и другие физические настройки
** изменение/удаление происходит через вставку нового значения в колонку с TS
*** при select выбираются последние 3 изменения (если в колонке не было изменений, то берется предыдущая максимальная версия)
** промежуточные данные хранятся в memstore сервера и логе изменений
*** периодически данные из памяти скидываются на hdfs
** hfile - мапится в файл hdfs, который также splitit'ится на разные сервера
** сжатие файлов хранилища:
*** объединение файлов CF в один
*** очистка от удаленных записей
Массовость - деление данных на сервера по:
* по семейству колонок
* по диапазону ключей
* по версии строки
* сам файл разбивается в hdfs на сплиты
Cassandra
отличия:** есть sql, а не только java api
** CF имеют иерархичность и могут также объединяться в группы по какомуто признаку
** настраевая consistency от самой строгой - ожидание отклика всех серверов, то записи без проверок
** нет единой точки отказа hmaster, данные делятся по диапазону
** но усложняет деление и поиск данных
* greenplum - классическая колоночная бд, с шардирование данных на основе pgsql
** есть поддержка sql
Spark
Альтернативный вариант реализации hadoop.* Преимущества перед hadoop:
1. Необязательно сохранять промежуточные результаты в HDFS при итеративной разработке. Данные можно хранить в памяти.
2. Необязательно чередовать map-reduce, можно делать несколько reducer подряд
3. Операции в памяти (вкллючая синхронизацию между серверами), а не через hdfs
4. Возможность загрузить данные в распределенную память, а потом делать обработку (каждому mapper уже не надо считывать данные из hdfs)
* В основе может лежать любой вид хранилища данных
* Архитектура, как в hadoop: name node (driver) + worker
* Основная составляющая вещь - RDD:
** объект партицируется
** каждая партиция имеет произвольное хранение: память, диск, hdfs и т.д.
*** Для хранения данных в памяти используется LRU буфер.
Старые, редко используемые данны вытесняются в медленное хранилище
** объект неизменяем (изменение создает новый объект)
** rdd распределена по серверам
* Программа состоит из однонаправленного графа операций без циклов
Виды зависимостей в графе:
** Narrow (узкая) - переход 1 партииции в 1 другую
** wide (широкая) - переход 1 (N) партиций в N (1)
* Восстановление в случае падения:
- нет репликации как в hdfs
+ для воостановления используется перезапуск
** если потерялись данные из одной партиции в Narrow связи, то восстанавливается только она из предыдущей партиции
** если в wide то перезапускаются все партиции (т.к. связ не 1 к 1).
Результат wide поумолчанию сохраняется на диск.
** Если есть шанс потерять данные, а цепочка длинная, то лучше самим самостоятельно сохранять промежуточные результаты на диск.
* Типы операции состоят из:
** Трансформация - не запускают работу
map, filer, group, union, join ....
** Действий - запускают работу (все трансформации в графе до этого графа)
count, collect, save, reduce
* spark поддерживает:
** java
** scala
** python
Join на scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val sc = new SparkContext(master, appName, [sparkHome], [jars])
//transform
//или из текстового файла sc.textFile("file.txt")
val visits = sc.parallelize(
Seq(("index.html", "1.2.3.4"),
("about.html", "3.4.5.6"),
("index.html", "1.3.3.1")))
val pageNames = sc.parallelize(
Seq(("index.html", "Home"),
("about.html", "About")))
visits.join(pageNames)
//action
visits.saveAsTextFile("hdfs://file.txt")
// ("index.html", ("1.2.3.4", "Home"))
// ("index.html", ("1.3.3.1", "Home"))
// ("about.html", ("3.4.5.6", "About"))
word count
val file = sc.textFile("hdfs://...")
val sics = file.filter(_.contains("MAIL"))
val cached = sics.cache()
val ones = cached.map(_ => 1)
val count = ones.reduce(_+_)
val file = sc.textFile("hdfs://...")
val count = file.filter(_.contains(“MAIL")).count()
или
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")
* Переменные для обмена данными между серверами
** broadcast variables - переменная только для чтения
val broadcastVar = sc.broadcast(Array(1, 2, 3)) ... broadcastVar.value** Accumulators - счетчики
val accum = sc.accumulator(0) accum += x accum.value
Yarn
планировщик ресурсов, которые избавляет от недостатков классического MR:* жесткое разделенеи ресурсов: можно освободить ресурсы от mapper после их полного выполнения и отдать все ресурсы reducer
* возможность разделять ресурсы не только между MR Задачами, но и другими процессами
* разделение происходит в понятии: озу, cpu, диск, сеть и т.д.
* он же производит запуск задач (не только MR) и восстанавливает в случае падения
* для работы нужны вспомогательные процессы:
** appserver - получение комманд от клиента
** resource server - север для выделяющий ресурсы
** node server - сервер для запуска задач и отслеживания за ними (на каждом сервере)
пятница, 17 февраля 2017 г.
Oracle: Hash агрегация и приблизительный DISTINCT
Список статей о внутреннем устройстве Oracle:
Нововведение Oracle 12.1 - приблизительный подсчет уникальных значений ( APPROX_COUNT_DISTINCT ~= count distinct ).
Классический подход к расчету числа уникальных значений предполагает создание хэш массива, где ключ = колонке таблицы, а в значении число совпадений.
Число элемнтов в хэш массиве будет равно числу уникальных данных в колонке таблицы:
Этот способ всем хорош, пока у нас достаточно памяти под хранение хэш массива.
При росте размера данных время и потребляемые ресурсы начинают катастрофически расти.
Пример со страницы antognini с разным числом уникальных значений на 10 млн. строк:
Скорость вычислений классическим способом падает вместе с ростом числа уникальных значений:
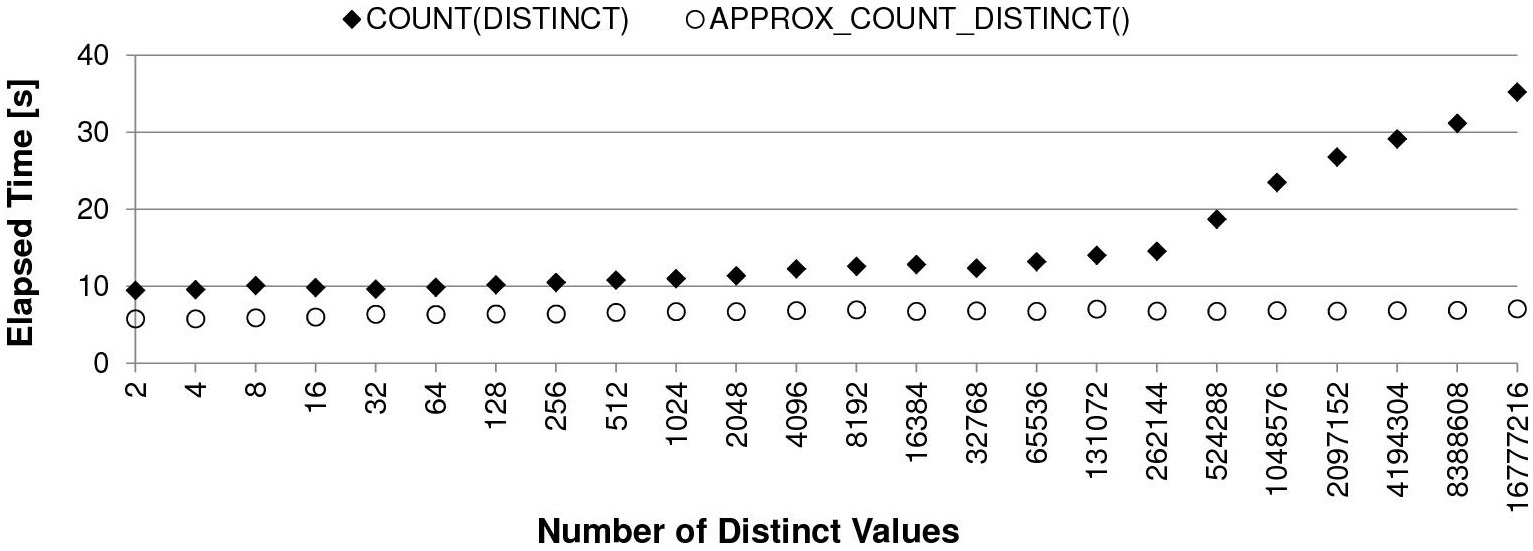
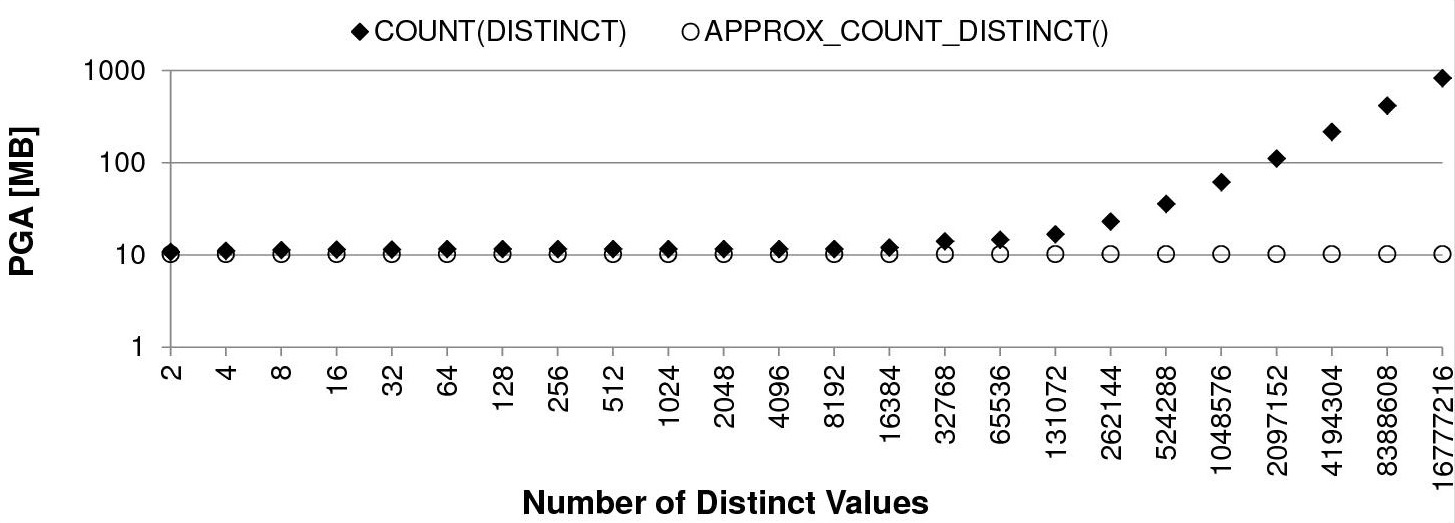
Пропорционально времени работы растет и потребление PGA памяти под хранение хэш массива:
Чтобы решить проблему производительности/памяти и при этом получить приемлемый результат, можно применить приблизительный расчет числа уникальных значений.
Как и bloom filter он основан на вероятностных хэш значениях от данных.
Общий смысл приблизительного расчета (habr):
1. От каждого значения берется произвольная хэш функция
2. У каждого хэш значения определяется ранк первого ненулевого бита справа.
Вероятность того, что мы встретим хеш с рангом 1 равна 0.5, с рангом 2 — 0.25, с рангом r — 1 / 2ранг
Если запоминать наибольший обнаруженный ранг R, то 2R сгодится в качестве грубой оценки количества уникальных элементов среди уже просмотренных.
Такой подход даст нам приблизительное число уникальных значений, но с сильной ошибкой.
Для данного алгоритма есть усовершенствованный вариант HyperLogLog:
а. От битового представления хэш берется 8 первых левых бит. Они становятся ключом массива (2^8 = 256 значений)
б. Над массивов вычисляется формула:

где am - корректирующий коэффициент, m - размер массива = 256, M[] - массив ранков (hashes)
Для погрешности в 6.5% числитель этой формулы будет равен константе = 47072.7126712022335488.
Остается в цикле возвести 2 в -степень максимального ранка из каждого элемента массива:
Данный алгоритм уже дает приемлемый результат на больших данных, но серьезно ошибается на небольшом наборе.
Для небольших значение применяется дополнительная математическая корректировка:
Проведенных тест на 1-2 томах войны и мира показал результаты:
* реальное количество уникальных слов = 3737
* приблизительное число уникальных слов основываясь только на максимальном ранке первого ненулевого бита справа = 16384
* приблизительное число уникальных слов по формуле из п. б на массиве из 256 элементов = 3676
* приблизительное число уникальных слов по формуле и корректировке = 3676
При ошибке числа уникальных значений в 6,1% мы затратили константное число памяти под массив из 256 элементов, что в разы меньше, чем при обычном хэш массиве.
Полный исходный код на java можно посмотреть на github
- Order by сортировка
- BTree индекс
- Hash Join
- Bloom filter
- Lru cache
- Hash агрегация и приблизительный DISTINCT
Нововведение Oracle 12.1 - приблизительный подсчет уникальных значений ( APPROX_COUNT_DISTINCT ~= count distinct ).
Классический подход к расчету числа уникальных значений предполагает создание хэш массива, где ключ = колонке таблицы, а в значении число совпадений.
Число элемнтов в хэш массиве будет равно числу уникальных данных в колонке таблицы:
class RealDist {
HashMap words;
public RealDist() {
words = new HashMap();
}
public void set(String word) {
if (!words.containsKey(word)) {
words.put(word, 1);
} else {
words.put(word, words.get(word) + 1);
}
} //set
public int get() {
return words.size();
} //get
} // RealDist
Этот способ всем хорош, пока у нас достаточно памяти под хранение хэш массива.
При росте размера данных время и потребляемые ресурсы начинают катастрофически расти.
Пример со страницы antognini с разным числом уникальных значений на 10 млн. строк:
CREATE TABLE t
AS
WITH
t1000 AS (SELECT /*+ materialize */ rownum AS n
FROM dual
CONNECT BY level <= 1E3)
SELECT rownum AS id,
mod(rownum,2) AS n_2,
mod(rownum,4) AS n_4,
mod(rownum,8) AS n_8,
mod(rownum,16) AS n_16,
mod(rownum,32) AS n_32,
mod(rownum,64) AS n_64,
mod(rownum,128) AS n_128,
mod(rownum,256) AS n_256,
mod(rownum,512) AS n_512,
mod(rownum,1024) AS n_1024,
mod(rownum,2048) AS n_2048,
mod(rownum,4096) AS n_4096,
mod(rownum,8192) AS n_8192,
mod(rownum,16384) AS n_16384,
mod(rownum,32768) AS n_32768,
mod(rownum,65536) AS n_65536,
mod(rownum,131072) AS n_131072,
mod(rownum,262144) AS n_262144,
mod(rownum,524288) AS n_524288,
mod(rownum,1048576) AS n_1048576,
mod(rownum,2097152) AS n_2097152,
mod(rownum,4194304) AS n_4194304,
mod(rownum,8388608) AS n_8388608,
mod(rownum,16777216) AS n_16777216
FROM t1000, t1000, t1000
WHERE rownum <= 1E8;
Скорость вычислений классическим способом падает вместе с ростом числа уникальных значений:
Пропорционально времени работы растет и потребление PGA памяти под хранение хэш массива:
Чтобы решить проблему производительности/памяти и при этом получить приемлемый результат, можно применить приблизительный расчет числа уникальных значений.
Как и bloom filter он основан на вероятностных хэш значениях от данных.
Общий смысл приблизительного расчета (habr):
1. От каждого значения берется произвольная хэш функция
public static int fnv1a(String text) {
int hash = 0x811c9dc5;
for (int i = 0; i < text.length(); ++i) {
hash ^= (text.charAt(i) & 0xff);
hash *= 16777619;
}
return hash >>> 0;
} //fnv1a
2. У каждого хэш значения определяется ранк первого ненулевого бита справа.
// позиция первого ненулевого бита справа
public static int rank(int hash, int max_rank) {
int r = 1;
while ((hash & 1) == 0 && r <= max_rank) {
r++;
// смещаем вправо, пока не дойдет до hash & 1 == 1
hash >>>= 1;
}
return r;
} //rank
Вероятность того, что мы встретим хеш с рангом 1 равна 0.5, с рангом 2 — 0.25, с рангом r — 1 / 2ранг
Если запоминать наибольший обнаруженный ранг R, то 2R сгодится в качестве грубой оценки количества уникальных элементов среди уже просмотренных.
Такой подход даст нам приблизительное число уникальных значений, но с сильной ошибкой.
Для данного алгоритма есть усовершенствованный вариант HyperLogLog:
а. От битового представления хэш берется 8 первых левых бит. Они становятся ключом массива (2^8 = 256 значений)
public void set(String word) {
int hash = fnv1a(word);
// убираем 24 бита из 32 справа - остается 8 левых
// (=256 разных значений)
int k = hash >>> 24;
// если коллизия, то берем наибольший ранк
hashes[k] = Math.max(hashes[k], rank(hash, 24));
} // count
б. Над массивов вычисляется формула:
где am - корректирующий коэффициент, m - размер массива = 256, M[] - массив ранков (hashes)
Для погрешности в 6.5% числитель этой формулы будет равен константе = 47072.7126712022335488.
Остается в цикле возвести 2 в -степень максимального ранка из каждого элемента массива:
public double get_loglog() {
double count = 0;
for (int i = 0; i < hashes.length; i++) {
count += 1 / Math.pow(2, hashes[i]);
}
return 47072.7126712022335488 / count;
} //get_loglog
Данный алгоритм уже дает приемлемый результат на больших данных, но серьезно ошибается на небольшом наборе.
Для небольших значение применяется дополнительная математическая корректировка:
public int get() {
long pow_2_32 = 4294967296L;
double E = get_loglog();
// коррекция
if (E <= 640) {
int V = 0;
for (int i = 0; i < 256; i++) {
if (hashes[i] == 0) {
V++;
}
}
if (V > 0) {
E = 256 * Math.log((256 / (double) V));
}
} else if (E > 1 / 30 * pow_2_32) {
E = -pow_2_32 * Math.log(1 - E / pow_2_32);
}
// конец коррекции
return (int) Math.round(E);
} //get
Проведенных тест на 1-2 томах войны и мира показал результаты:
* реальное количество уникальных слов = 3737
* приблизительное число уникальных слов основываясь только на максимальном ранке первого ненулевого бита справа = 16384
* приблизительное число уникальных слов по формуле из п. б на массиве из 256 элементов = 3676
* приблизительное число уникальных слов по формуле и корректировке = 3676
При ошибке числа уникальных значений в 6,1% мы затратили константное число памяти под массив из 256 элементов, что в разы меньше, чем при обычном хэш массиве.
Полный исходный код на java можно посмотреть на github
Подписаться на:
Комментарии (Atom)