- Order by сортировка
- BTree индекс
- Hash Join
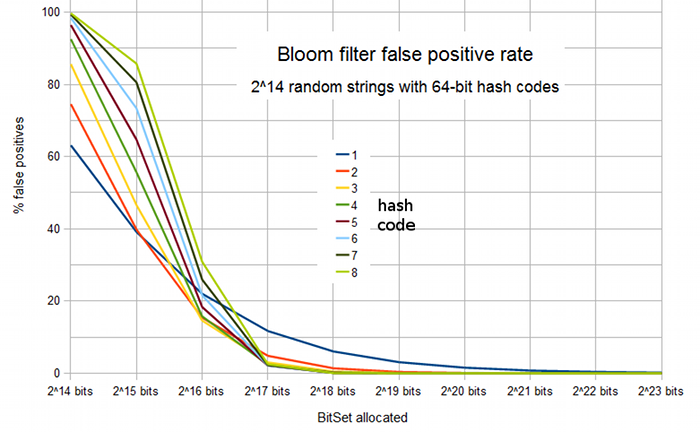
- Bloom filter
- Lru cache
- Hash агрегация и приблизительный DISTINCT
Следующий аспект больших бд, у которых все данные не способны поместиться в памяти - кеширование частоиспользуемых данных в памяти.
 В Oracle для кэширования используется модифицированный алгоритм LRU.
В Oracle для кэширования используется модифицированный алгоритм LRU.Lru (least recent used) кэш — буфер в памяти для быстрого доступа к часто используемым элементам.
Lru кэш представляет из себя двусвязный список (2Linked List), вначале которого наиболее часто используемые элементы, а в конце - редко.
Для ускорения произвольного доступа над списком создается хэш массив (Hash Map) ссылок на элементы двусвязанного списка:
Раньше я уже описывал lru кэш со стороны разработчика бд: Ядро oracle, сегодня копнем немного глубже, с кодом lru кэша на java.
Двусвязный список с дополнительным счетчиком обращений для хранения LRU:
//двухсвязный список
class Node<Value> {
//ключ списка
int key;
//абстрактное значение
Value value;
//счетчик обращений к элементу
int cnt;
//указатель на предыдущий элемент
Node prev;
//указатель на следующий элемент
Node next;
//элемент был перемещен из конца списка в начало
boolean swaped;
public Node(int key, Value value){
this.key = key;
this.value = value;
this.cnt = 1;
this.swaped = false;
}
При обращении к элементу списка увеличиваем счетчик обращений "cnt":
//получить значение из списка
public Value getValue() {
//увеличиваем счетчик обращений
cnt++;
//сбрасываем признак смещений, если элемент был прочитан
this.swaped = false;
return value;
}
//установить значение
public void setValue(Value val) {
this.value = val;
//также увеличиваем счетчик
cnt++;
//сбрасываем признак смещений, если элемент был перезаписан
this.swaped = false;
} //setValue
} //Node
Класс Lru дополняется хэш массивом "map" в котором для ускорения доступа количество хэш секций (capacity) >= числу элемнтов в списке;
И стандартные указатель на начало "head" и конец "end" списка.
Дополнительное изменение в Oracle - указатель на середину списка "cold", где начинаются холодные данные.
public class Lru<Value> {
//доступной число элементов в кэше
int capacity;
//хэш массив элементов для быстрого доступа
HashMap<Integer, Node> map;
//указатель на начало (горячие элементы)
Node head = null;
//указатель на середину (начало холодных элементов)
Node cold = null;
//указатель на конец (самый редкоиспользуемый)
Node end = null;
//число элементов в кэше
int cnt;
//конкструктор с числом элементов в кэше
public Lru (int capacity) {
this.capacity = capacity;
//хэш массив создаем с нужным числом секций = загруженности
map = new HashMap<Integer, Node>(capacity);
}
Для получения элемента используется хэш массив, без последовательного просмотра всего списка:
//получить элемент из кэша
public Value get(int key) {
//быстрое извлечение их хэш массива
if(map.containsKey(key)) {
//и инкремент счетчика обращений
return (Value) map.get(key).getValue();
}
return null;
} //get
Если элементов в списке меньше размер буфера, то используется обычный алгоритм LRU - новые элементы добавляются в начало списка, а старые вытесняются вправо, пока не дойдут до конца списка.
//места достаточно, добавляем вначало
protected void addHead(Node n) {
//первый элемент
if(this.head == null) {
//устанавливаем начало и конец = элементу
this.head = n;
this.end = n;
} else {
//вставляем вначало
//следующий для нового элемента = начало списка
n.next = this.head;
//предыдущий для начала списка = новый элемент
this.head.prev = n;
this.head = n;
//второй элемент
if(this.end.prev == null) {
//предыдущий для конца = новый элемент
this.end.prev = n;
}
}
//устанавливаем середину
if(cnt == capacity / 2) {
this.cold = n;
}
//счетчик элементов + 1
cnt++;
} //addHead
У этого подхода есть существенный минус: редкоиспользуемый элемент может случайно вытеснить из списка популярный блок, который не вызывался небольшой период времени, за который он успел сместиться до конца.
Для решения этой проблемы Oracle применяет 2 подхода:
1. Если в конце элемент со счетчиком обращений = 1, то он открепляется от списка, а новый блок помещается в среднюю точку cold.
Для этого ссылки соседей открепляются друг от друга и перенацеливаются на новый блок, который становится новой серединой.
//удаляем конца списка
private void delEnd() {
//из хэш массива
map.remove(this.end.key);
//и делаем концом списка = предыдущий элемент
this.end = this.end.prev;
this.end.next = null;
} //delEnd
//вконце малопопулярный блок
protected void addColdUnPop(Node n) {
//удаляем конец
delEnd();
//у старой середины изменяем счетчик на 1
if(this.cold.swaped) {
//если смещенный элемент не был ни разу считан
//и дошел до середины,
//то сбрасываем счетчик в 1
this.cold.cnt = 1;
this.cold.swaped = false;
}
//новый блок в середину = cold
//проставляем ссылки у нового элемента
n.prev = this.cold.prev;
n.next = this.cold;
//и разрываем связи и соседей
n.prev.next = n;
n.next.prev = n;
this.cold = n;
} //addColdUnPop
2. Если в конце популярный элемент со счетчиком > 1 , тогда последний блок открепляется, счетчик обращений делится на 2 и этот блок перемещается в начало списка.
Такой элемент помечается флагом swaped = true, который сбрасывается при любом последующем обращении к элементу.
Это предотвращает случайное вытеснение популярного блока из памяти.
Середина списка также смещается влево, одновременно делая число обращений = 1 у новой элемента-середины, если к ней никто не обращался за время смещения от начала до середины (swaped = true).
Новый блок помещается в центр списка cold.
//вконце популярный блок
protected void addColdPop(int key, Value value) {
//делим счетчик на пополам
this.end.cnt = this.end.cnt / 2;
//открепляем конец
Node n = this.end;
//удаляем конец
delEnd();
//конец перемещаем в начало
n.prev = null;
n.next = this.head;
this.head.prev = n;
this.head = n;
//помечаем, что элемент был перемещен из конца в начало
this.head.swaped = true;
//смещаем середину на 1 влево
if(this.cold.swaped) {
//если смещенный элемент не был ни разу считан
//и дошел до середины,
//то сбрасываем счетчик в 1
this.cold.cnt = 1;
this.cold.swaped = false;
}
this.cold = this.cold.prev;
//рекурсивно пытаемся вставить вконец
//TODO: если все популярные? то вставка будет идти очень долго
this.set(key, value);
} //addColdPop
События ожиданий связанные с наполнением буферного кэша:
* Buffer busy waits / read by other session - сессия пытается считать блок, который сейчас читается в кэш или модифицируется в кэше другой сессией.
Полный исходный код можно посмотреть тут: https://github.com/pihel/java/blob/master/cache/lru.java

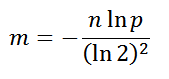

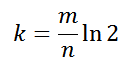
 Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место.
Коллизии размещаются в томже хэш массиве, но смещаются вправо, пока не найдется свободное место. Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции.
Хэш таблица содержит список коллизий. Число элементов хэш таблицы фиксировано = числу различных вариантов хэширующей функции. Слева графически представлен механизм поиска в хэш таблице Oracle.
Слева графически представлен механизм поиска в хэш таблице Oracle.